|
|
このテクニカルノートでは、HFS Plus ボリュームのオンディスクフォーマットについて説明します。 ただし、HFS Plus ボリュームに関するプログラミングインタフェースについては説明しません。
このテクニカルノートは、File Manager プログラミングインタフェースによって提供される抽象層の下位にある非常にローレベルな層で HFS Plus を使った作業を必要とするデベロッパ向けに書かれています。 この中には、ディスク修復ユーティリティのデベロッパや、HFS Plus のサポートを他のプラットフォームにインプリメントしようとしているプログラマなどが含まれます。
このテクニカルノートでは、読者が「Inside Macintosh: Files」に記載されている HFS ボリュームに関する基本概念を十分に理解していることを前提にします。
[2004 年 5 月 5 日]
|
HFS Plus の基礎
HFS Plus は、MacOS のボリュームフォーマットです。 HFS Plus は、Mac OS 8.1 から導入されました。 HFS Plus のアーキテクチャは HFS にきわめて似ていますが、いくつかの変更が加えられています。 次に、重要な相違点をまとめた一覧表を示します。
表 1 HFS と HFS Plus の比較
|
機能
|
HFS
|
HFS Plus
|
利点/コメント
|
|
ユーザに表示される名前
|
Mac OS 標準
|
Mac OS 拡張
|
|
|
アロケーションブロックの数
|
16 ビット相当
|
32 ビット相当
|
大容量ボリュームで使用されるディスク領域が大幅に減少する。 同時に、ボリュームに格納できるファイル数が増大する。
|
|
長いファイル名
|
31 文字
|
255 文字
|
ユーザにとっては明らかな利点であると同時に、クロスプラットフォームの互換性を向上させる。
|
|
ファイル名のエンコーディング
|
MacRoman
|
Unicode
|
スクリプトが混在する名前を含めて、世界各国の言語に対応したファイル名を使用できるようになる。
|
|
ファイル/フォルダの属性
|
固定長サイズの属性をサポート (FileInfo と ExtendedFileInfo)
|
将来のメタデータ機能拡張の先取り
|
将来のシステムでは、より豊かな Finder 操作を実現するためのメタデータを使用する可能性がある。
|
|
OS のスタートアップサポート
|
システムフォルダ ID
|
専用のスタートアップファイルもサポート
|
非 Mac OS システムが HFS Plus ボリュームからブートすることを可能にする。
|
|
カタログノードサイズ
|
512 バイト
|
4KB
|
他の変更に対応してボリュームの効率を維持する。 非常に長いファイル名(31 文字の名前に対しては 512 バイト)と、より長いカタログデータ(フィールド数がより多くなり、フィールドのサイズもより大きくなったため)がサポートされたため、カタログノードサイズがこのように大きくなった。
|
|
最大のファイルサイズ
|
231 バイト
|
263 バイト
|
ユーザ、特にマルチメディアコンテンツのクリエータにとっては朗報。 |
これらの HFS Plus の機能をどの程度までプログラミングインタフェースを介して使用できるかは OS によります。 バージョン 9.0 以前の Mac OS では HFS Plus 固有の機能に対応するプログラミングインタフェースを提供していません。
まとめると、HFS Plus ボリュームフォーマットの設計を導いた主な目標は、次のとおりでした。
- ディスク領域の効率的な使用
- 世界各国の言語に対応したファイル名
- 将来計画されている名前付きフォークのサポート
- 非 Mac OS オペレーティングシステムにおけるブートの簡易化
次のセクションでは、これらの目標と、これらの目標を実現するための HFS と HFS Plus に対する要求の相違について説明します。
ディスク領域の効率的な使用
HFS では、ボリューム上の領域全体をアロケーションブロックと呼ばれる等しいサイズの小区画に分割します。 HFS は 16 ビットのフィールドを使って特定のアロケーションブロックを識別するため、HFS ボリューム上のアロケーションブロックの数は 216 (65,536) 未満でなければなりません。 通常、1 つのアロケーションブロックのサイズは、ボリューム上のアロケーションブロックの数が 65,536 未満となるような 512 の最小倍数です(つまり、ボリュームサイズを 65,535 で割り、それを 512 の倍数に丸めた値)。 空でないフォークは、整数個のアロケーションブロックを占有する必要があります。 これは、1 つのフォークによって占有される領域の容量がアロケーションブロックサイズの倍数に切り上げられるという意味です。 ボリューム (およびアロケーションブロック) のサイズが大きくなるにつれ、割り当てられても未使用のまま残される領域の容量がだんだん多くなります。
一方、HFS Plus では 32 ビット値を使ってアロケーションブロックを識別します。 これにより、1 つのボリューム上に最大 2 32(4,294,967,296)までのアロケーションブロックを作成できるようになります。 特に 1GB またはそれ以上のサイズのボリュームで、アロケーションブロック数が多くなればなるほど、アロケーションブロックのサイズは小さくなると同時に、浪費される領域(フォークの末尾にある半端なアロケーションブロック。このようなアロケーションブロック全体は実際には使用されません)も少なくなります。 また、このことは、使用可能な領域を多数のファイルの間でより細かく分配できるようになるため、より多くのファイルをボリュームに格納できるということを意味します。 この変更は、ボリュームにサイズの小さなファイルが多数含まれる場合には特に役立ちます。
世界各国の言語に対応したファイル名
HFS では 31 バイトの文字列を使ってファイル名を格納します。 ファイル名とともに、ファイル名を解釈する方法を指定する何らかのスクリプト情報が格納されることはありません。 ファイル名は Roman スクリプトを前提とするルーチンを使って比較されてソートされます。 このため、Roman スクリプト以外のスクリプト(日本語など)を使用している名前の扱いが台なしになってしまいます。 しかも悪いことに、このアルゴリズムはバグだらけで、Roman スクリプトで使用する場合でさえ問題が起こります。 たとえば、Finder やその他のアプリケーションは、実行時に使用されているスクリプトに基づいてファイル名を解釈してしまいます。
|
注意:
HFS ファイル名で非 Roman スクリプトを使用する際の問題は、HFS が大小文字の区別を無視してファイル名を比較するということです。 この大小文字を区別しない比較アルゴリズムは MacRoman エンコーディングを前提にしています。 このため非 Roman テキストを使ったファイル名を取り扱うとき、このアルゴリズムには奇妙なエラーが発生します。 つまり、ソースエンコーディングではファイル名の重複は発生していないのに、HFS は特定の非 Roman ファイル名が他のファイル名と重複していると判断してしまいます。
|
HFS Plus では、最大 255 までの Unicode 文字を使ってファイル名を格納します。 ファイル名に 255 文字まで使用できるようになることで、内容を説明したわかりやすいファイル名を付けることが容易になります。 名前がコンピュータによって自動的に生成されるとき(Java のクラス名など)、長い名前は特に便利です。
HFS のカタログ B ツリーは 512 バイトのノードを使用します。 HFS Plus のファイル名は最大で 512 バイトまでを占有できます(長さフィールドを含めて)。 B ツリーのインデックスノードは少なくとも 2 つのキー(およびポインタとノードディスクリプタ)を格納する必要があるため、HFS Plus のカタログはより大きなノードサイズを使用する必要があります。 HFS Plus カタログ B ツリーの典型的なノードサイズは 4KB です。
HFS のカタログ B ツリーの場合、インデックスノードに格納されるキーは最大のキーサイズに対応する固定長の容量を常に占有します。 HFS Plus の場合、インデックスノードのキーは実際のキーのサイズによって決まる可変長の容量を占有します。 これにより、インデックスノード内の無駄な領域がなくなり、通常のディスクでは、ツリー内に効率のよい枝分かれ構造が作成されます(その結果、指定されたレコードを検出するために必要なノードアクセスの回数が少なくなります)。
将来計画されている名前付きフォークのサポート
HFS ボリューム上のファイルは、データフォークとリソースフォークという 2 つのフォークを持ち、これらのいずれかが空(長さがゼロ)であることもあります。 また、ファイルとディレクトリには、修正日や Finder 情報などの、ごくわずかな追加情報(カタログ情報またはメタデータと呼ばれます)が含まれます。
Apple のソフトウェアチームやサードパーティのデベロッパは、これまでしばしば、特定のファイルやディレクトリに関連する情報を格納しなければならないことがありました。 いくつかの場合では(たとえば、ファイルのカスタムアイコン)、データまたはリソースフォークが最適な格納場所になります。 しかし場合によっては(たとえば、ディレクトリのカスタムアイコン、あるいはファイル共有アクセスの特権)、データまたはリソースフォークを使用することが適切でなかったり、そもそも不可能なこともあります。
いくつかの製品には、ファイルおよびディレクトリ関連データを格納するための特殊用途のソリューションがインプリメントされています。 しかし、これらのソリューションはファイルシステムによって管理されていないため、ファイルおよびディレクトリ構造との間に不一致が発生する場合があります。
HFS Plus には、アトリビュートファイル、つまり、ファイルやディレクトリの追加情報を格納するために使用できる第 2 の B ツリーがあります。 このファイルはボリュームフォーマットの一部であるため、その情報は移動や名前の変更を行ってもファイルやディレクトリとともに保持され、ファイルやディレクトリを削除すると自動的に削除されます。 アトリビュートファイルのレコードの内容はまだ完全には定義されていませんが、最終的にはそれぞれのファイルやディレクトリに対応する任意の数のフォーク(Unicode 名によって識別される)を提供することになるはずです。
|
注意:
アトリビュートファイルはまだ完全に定義されていないため、現在のインプリメンテーションでは、ファイルまたはディレクトリが削除されたときに名前付きフォークを削除することができません。 名前付きフォークを適切に削除する将来のインプリメンテーションでは、これらの孤立した名前付きフォークをチェックして、ボリュームをマウントするときにそれらを削除する必要があります。 ボリュームヘッダーの lastMountedVersion フィールドは、このようなチェックを行う必要があることを検出するために使用できます。
アプリケーションでは、名前付きフォークを孤立させるのではなく、できるかぎり削除するようにしてください。
|
代替オペレーティングシステムの容易なスタートアップ
HFS Plus では特殊なスタートアップファイルが定義されています。これは、システムのスタートアップ時に容易に検出することのできる構造化されていないフォークです。 スタートアップファイルの保存場所とサイズはボリュームヘッダーに記述されています。 スタートアップファイルは、HFS または HFS Plus が ROM でサポートされていないシステムで特に役立ちます。 多くの点で、スタートアップファイルは HFS のブートブロックを一般化したもの、つまり、より大きな可変サイズの記憶容量を提供するブートブロックといえます。
先頭に戻る
コアとなる概念
HFS Plus は相互に関連するいくつかの構造を使って、ボリューム上のデータの構成を管理します。 これらの構造には次のものが含まれます。
これらの複雑な構造については、それぞれ独立したセクションで説明します。 このセクションでは、個別の構造の説明を始める前に、ボリュームフォーマットの概要を示し、それぞれの構造相互の関係を説明した上、HFS Plus によって使用されるプリミティブなデータ型を定義します。
用語の定義
HFS Plus は、ボリューム(ユーザデータおよびそのデータを取り出すための構造を含んだファイル)がディスク(ユーザデータが格納されるメディア)上にどのように存在するかを規定した仕様です。 ディスク上の記憶領域は、セクタと呼ばれる単位に分割されています。 セクタは、ディスクのドライバソフトウェアが 1 回の操作で(要求されたデータの前後に追加のデータの読み書きを行う必要なしに)読み取ったり書き込んだりするディスク領域の最小単位です。 通常、セクタのサイズは、データがディスク上に物理的に配置されている方法に基づいています。 ハードディスクでは、セクタは一般に 512 バイトです。 光メディアでは、セクタは一般に 2048 バイトです。
ジャーナルを除く HFS Plus ボリューム上の大半のデータ構造は、セクタのサイズに依存しません。 ジャーナルは、個々のセクタへのアクセスに依存するため、セクタのサイズはジャーナルヘッダーの jhdr_size フィールドに格納されます(ボリュームにジャーナルが存在する場合)。
HFS Plus は領域の割り当てを、アロケーションブロックと呼ばれる単位で行います。アロケーションブロックとは、連続するバイトを単純に 1 つのグループとしてまとめたものです。 1 つのアロケーションブロックのサイズ(バイト単位)は 512 以上の 2 のべき乗の値であり、ボリュームの初期化時に設定されます。 ボリュームを再初期化しないかぎり、この値を容易に変更することはできません。 アロケーションブロックは、32 ビットのアロケーションブロック番号によって識別されるため、ボリューム上には最大で 232 個のアロケーションブロックが存在できることになります。 ファイルシステムの現在のインプリメンテーションは、サイズが 4K のアロケーションブロックに最適化されています。
|
注意:
最良のパフォーマンスを得るには、アロケーションブロックサイズをセクタサイズの倍数にします。 ボリュームに HFS ラッパーがある場合には、ラッパーのアロケーションブロックサイズと、アロケーションブロックの開始位置も、最良のパフォーマンスを得るためにセクタサイズの倍数にします。
|
ボリュームヘッダーを含めて、これらのボリュームの構造はすべて 1 つまたは複数のアロケーションブロックの一部です(ただし、代替ボリュームヘッダーは該当しない場合があります。詳細は後述のとおりです)。 この点が HFS とは異なります。HFS には、どのアロケーションブロックにも属さないいくつかの構造(ブートブロック、マスターディレクトリブロック、ビットマップなど)が存在します。
ファイルの連続性を高めてフラグメンテーションを避けるため、通常、ディスク領域は複数のアロケーションブロックのグループであるファイル、つまりクランプに割り当てられます。 クランプのサイズは、必ずアロケーションブロックサイズの倍数です。 デフォルトのクランプサイズは、ボリュームヘッダーに指定されてます。
|
重要:
ファイルの拡張に使用される実際のアルゴリズムはこの仕様の一部ではありません。 インプリメンテーションがボリュームヘッダーに含まれるクランプ値に基づいて動作する必要はありません。ボリュームヘッダーは、これらの値を格納するための領域を提供するだけです。
|
|
注意:
Mac OS で採用している現在の非連続アルゴリズムは検出された次の空きブロックで割り当てを開始します。 リクエストされたアロケーションの末尾に続く十分な空き領域が存在する場合、このアルゴリズムはクランプサイズの倍数になるまでその割り当てを拡張します。 つまり、領域が連続するクランプサイズの断片に割り当てられるわけではありません。
|
どの HFS Plus ボリュームもボリュームヘッダーを持っていなければなりません。 ボリュームヘッダーには、ボリュームの作成日時、ボリューム上にあるファイルの数、それにその他の重要な構造のボリューム上の位置など、ボリュームに関する雑多な情報が含まれています。 ボリュームヘッダーは、必ずボリュームの先頭から 1024 バイトの位置にあります。
代替ボリュームヘッダーと呼ばれるボリュームヘッダーのコピーは、ボリュームの末尾から 1024 バイトさかのぼった位置から始まる場所に格納されています。 ボリュームの先頭から 1024 バイト(ボリュームヘッダーの前)とボリュームの最後の 512 バイト(代替ボリュームヘッダーの後)は予約されています。 ボリュームヘッダー、代替ボリュームヘッダー、およびボリュームヘッダーと代替ボリュームヘッダーの前また後にある予約領域を含むアロケーションブロックはすべて、アロケーションファイルにおいて使用済みとしてマークされます。 このようにマークされたアロケーションブロックの実際の数は、アロケーションブロックサイズによって異なります。
1 つの HFS Plus ボリュームには 5 つの特殊ファイルが含まれており、これらの中にはフォルダ、ユーザファイル、属性といったファイルシステムの情報にアクセスするために必要なファイルシステム構造体が含まれています。 特殊ファイルとは、カタログファイル、エクステントオーバーフローファイル、アロケーションファイル、アトリビュートファイル、およびスタートアップファイルの 5 つです。 これらのファイルは単一のフォーク(データフォーク)のみを持ち、フォークのエクステントはボリュームヘッダー内に記述されています。
カタログファイルは、ボリューム上のフォルダとファイルの階層を記述する特殊ファイルです。 カタログファイルには、ボリューム上のすべてのファイルとフォルダに関する重要な情報と、カタログファイルに格納されているファイルとフォルダに対するカタログ情報が含まれています。 カタログファイルは、巨大なフォルダ階層の中をすばやくかつ効率的に検索できるように B ツリー(「バランスツリー」)として構成されています。
カタログファイルは、後述するように、ファイルとフォルダの名前を格納し、それらの名前は最大 255 文字までの Unicode 文字から構成されています。
|
注意:
HFS Plus によって使用される B ツリーの詳細については、「B ツリー」のセクションを参照してください。 |
アトリビュートファイルは、ファイルやフォルダの追加データを含むもう 1 つの特殊ファイルです。 カタログファイルと同様に、アトリビュートファイルも B ツリーとして構成されています。 将来、このファイルは追加フォークに関する情報の格納に使用される予定です (カタログファイルがファイルのデータフォークおよびリソースフォークに関する情報を格納する方法に似ています)。
HFS Plus では、フォークのエクステントのリストを保持することで、どのアロケーションブロックがそのフォークに属するかを追跡します。 エクステントとは、何らかのフォークに割り当てられたアロケーションブロックの連続する範囲のことで、先頭のアロケーションブロックの番号とアロケーションブロックの数という数値のペアによって表されます。 ユーザファイルの場合、それぞれのフォークの先頭から 8 つのエクステントはボリュームのカタログファイルに格納されます。 また、それ以上のエクステントはエクステントオーバーフローファイルに格納されます。なお、このファイルも B ツリーとして構成されています。
エクステントオーバーフローファイルは、自分自身を除く他の特殊ファイルの追加エクステントも格納します。 ただし、スタートアップファイルがボリュームヘッダーに 8 つを超えるエクステントを格納しなければならなくなると(その結果、エクステントオーバーフローファイルに追加エクステントを格納する必要があります)、アクセスが非常にむずかしくなり、スタートアップファイルの目的を果たさなくなってしまいます。 このため実際には、スタートアップファイルはエクステントオーバーフローファイルに追加エクステントを格納する必要がないように割り当てを行わなければなりません。
アロケーションファイルは、アロケーションブロックが使用済みであるかどうかを示す特殊ファイルです。 このファイルは、HFS ボリュームのビットマップと同じ役割を果たしますが、ファイルであることでボリュームフォーマットに柔軟性を与えられます。
スタートアップファイルは、非 Mac OS コンピュータを HFS Plus ボリュームからブートすることを可能にする別の特殊ファイルです。
最後に、不良ブロックファイルは、特定のアロケーションブロックを格納するメディアの一部に欠陥があるとき、ボリュームがそのアロケーションブロックを使用できないようにします。 不良ブロックファイルは特殊ファイルでもなければ、ユーザファイルでもありません。これは、エクステントオーバーフローファイルの中で使用される慣例にすぎません。 詳細については、「不良ブロックファイル」を参照してください。
幅広い構造
HFS Plus ボリュームの大半は 7 つのタイプの情報または領域から構成されています。
- ユーザファイルフォーク
- アロケーションファイル(ビットマップ)
- カタログファイル
- エクステントオーバーフローファイル
- アトリビュートファイル
- スタートアップファイル
- 未使用領域
図 1 に、HFS Plus ボリュームの一般的な構造を示します。

図 1. HFS Plus ボリュームの構成
ボリュームヘッダーは、必ず固定の位置にあります(ボリュームの先頭から 1024 バイト)。 しかし、その他の特殊ファイルは、ボリュームヘッダーブロックと代替ボリュームヘッダーブロックに挟まれた任意の位置に現れます。 これらのファイルは任意の順序で現れ、必ずしも連続していません。
HFS Plus ボリューム上の情報はアロケーションブロックのみによって構成されます(ただし、代替ボリュームヘッダーは例外となる場合があります。詳細は後述します)。 アロケーションブロックはメディア上の領域を、より使いやすい区画にグループ化する手段にすぎません。 1 つのアロケーションブロックのサイズは 512 以上の 2 のべき乗値になります。 アロケーションブロックのサイズは、ボリュームヘッダーのパラメータの 1 つであり、その値はボリュームを初期化するときに設定されます。ボリュームの再初期化を行わないかぎり、この値は変更することはほとんど不可能です。
|
注意:
アロケーションブロックサイズは、速度と領域の間のバランスという典型的な調整によって決まります。 アロケーションブロックサイズを大きくすると、アロケーションファイルのサイズが小さくなり、しばしば、各ファイルについて操作する必要のある個別のエクステントの数も少なくなります。 またこれにより、1 回のディスク I/O の平均サイズも大きくなる傾向があり、結果的にオーバーヘッドが減少します。 一方、アロケーションブロックサイズを小さくすると、1 つのファイルあたり無駄になる平均バイト数が減少し、ボリュームの領域をより有効に使用できるようになります。
|
|
警告:
アロケーションブロックサイズが 4 KB 未満の HFS Plus ディスクは認められてはいますが、DTS としてはアロケーションブロックサイズは最小でも 4 KB とすることをお勧めします。 それよりも小さいサイズのアロケーションブロックサイズのディスクは、Mac OS X Server のように 4 KB のクラスタ入出力を行うシステムでは速度が目に見えて低下します。
|
プリミティブなデータ型
このセクションでは、HFS Plus ボリュームで使用されるプリミティブなデータ型について説明します。 このボリュームで使用されるすべてのデータ型は C 言語で定義されています。 この仕様では、コンパイラがパディングフィールドを挿入しないことが前提になっています。 必要なパディングフィールドがあれば明示的に宣言されます。
|
重要:
HFS Plus ボリュームフォーマットは、大部分が HFS ボリュームフォーマットから派生しています。 しかし、この新しいフォーマットを定義する段階で、使用されていないフィールド(主として旧来の MFS フィールド)を削除し、類似したフィールドをグループ化し、すべてのフィールドに適切なアライメントを持たせる(PowerPC アライメント規則を使って)ように、残されたすべてのフィールドを再配置することが決定されました。
|
予約されているフィールドとパディングフィールド
この仕様では、多くの場所でフィールドまたはフィールド内のビットを予約済みと記述しています。 この記述は、次のように明確に限定された意味を持ちます。
- 予約されたフィールドを含む構造体を作成するとき、インプリメンテーションではそのフィールドをゼロに設定する必要があります。
- 既存の構造体を読み込むとき、インプリメンテーションではそのフィールドに含まれる値を無視する必要があります。
- 予約されたフィールドを含む構造体を変更するとき、インプリメンテーションでは予約されているフィールドの値を維持する必要があります。
この定義により、ボリュームフォーマットに対する下位互換性が強化されます。
パディングフィールドも予約されているフィールドとまったく同じ意味を持ちます。 名前の違いは、インプリメンテーションの動作の違いを示すものではなく、設計者がフィールドを含めたときの意図を反映したものにすぎません。
整数型
すべての整数値は次のプリミティブなデータ型のいずれかによって定義されます。 UInt8、SInt8、UInt16、SInt16、UInt32、SInt32、UInt64、および SInt64 これらのデータ型は符号なし、および符号付き(2 の補数)の 8 ビット、16 ビット、32 ビット、および 64 ビットの数値を表します。
すべてのマルチバイト整数値はビッグエンディアン(Big-endian)フォーマットで格納されます。 つまり、各バイトは、ブロックの先頭からのオフセットが大きくなるのに応じて、最上位バイトから最下位バイトまでの順に格納されます。 ビットの番号は 0 から n-1となり(型が UIntn および SIntn として)、ビット 0 が最下位ビットとなります。
HFS Plus の名前
HFS Plus のファイルおよびフォルダ名は、HFSUniStr255 型によって定義される、長さを示す 16 ビットの値が先頭に付いた、最大 255 文字までの Unicode 文字から構成されます。
struct HFSUniStr255 {
UInt16 length;
UniChar unicode[255];
};
typedef struct HFSUniStr255 HFSUniStr255;
typedef const HFSUniStr255 *ConstHFSUniStr255Param;
|
UniChar は、『The Unicode Standard, Version 2.0 [Unicode, Inc. ISBN 0-201-48345-9]』で定義されている Unicode 文字セットで定義された文字を表す UInt16 型の値です。
HFS Plus は完全に分解された文字列を標準的な順序で格納します。 HFS Plus は大小文字を区別せずに文字列を比較します。 文字列には Unicode 文字が含まれている場合があり、比較の際には無視する必要があります。 これらの問題の詳細については、「Unicode に関する微妙な問題」を参照してください。
HFS Plus のバリエーションである HFSX では、名前の大文字小文字が区別されるボリュームを持つことが可能です。 名前は完全に分解され、標準的な順序となっていますが、比較の際に Unicode 文字列は無視されません。
テキストエンコーディング
従来の Mac OS プログラミングインタフェースはファイル名を Pascal 文字列として渡します(StringPtr または FSSpec に埋め込まれた Str63 として)。 このような文字列に含まれる文字は Unicode ではありません。エンコーディングは、システムソフトウェアがローカライズされた方法とインストールされているランゲージキットによって異なります。 このため、同一のバイトのシーケンスがまったく異なる Unicode 文字のシーケンスを表すことがあります。 同様に、多くの Unicode 文字が複数の Mac OS テキストエンコーディングに属しています。
HFS Plus には、特に Mac OS エンコーディングの Pascal 文字列と Unicode との間の Mac OS での変換を支援するために設計された 2 つの機能が用意されています。 第 1 の機能は、ファイルおよびフォルダのカタログレコードに含まれる textEncoding フィールドです。 このフィールドは、レコードの Unicode 名を Mac OS エンコーディングの Pascal 文字列に変換するときに使用するヒントとして定義されています。
表 2 に、textEncoding フィールドに設定できる有効な値の定義を示します。
表 2 テキストエンコーディング
|
エンコーディング名
|
値
|
エンコーディング名
|
値
|
|
MacRoman
|
0
|
MacThai
|
21
|
|
MacJapanese
|
1
|
MacLaotian
|
22
|
|
MacChineseTrad
|
2
|
MacGeorgian
|
23
|
|
MacKorean
|
3
|
MacArmenian
|
24
|
|
MacArabic
|
4
|
MacChineseSimp
|
25
|
|
MacHebrew
|
5
|
MacTibetan
|
26
|
|
MacGreek
|
6
|
MacMongolian
|
27
|
|
MacCyrillic
|
7
|
MacEthiopic
|
28
|
|
MacDevanagari
|
9
|
MacCentralEurRoman
|
29
|
|
MacGurmukhi
|
10
|
MacVietnamese
|
30
|
|
MacGujarati
|
11
|
MacExtArabic
|
31
|
|
MacOriya
|
12
|
MacSymbol
|
33
|
|
MacBengali
|
13
|
MacDingbats
|
34
|
|
MacTamil
|
14
|
MacTurkish
|
35
|
|
MacTelugu
|
15
|
MacCroatian
|
36
|
|
MacKannada
|
16
|
MacIcelandic
|
37
|
|
MacMalayalam
|
17
|
MacRomanian
|
38
|
|
MacSinhalese
|
18
|
MacFarsi
|
140 (49)
|
|
MacBurmese
|
19
|
MacUkrainian
|
152 (48)
|
|
MacKhmer
|
20
|
|
|
|
重要:
HFS Plus の非 Mac OS インプリメンテーションでは、textEncoding フィールドを単純に無視することもできます。 この場合は、このフィールドを予約済みのフィールドとして取り扱うようにしてください。
|
|
注意:
Mac OS は、次のような方法で textEncoding フィールドを使用します。 ファイルまたはフォルダの作成または名前変更が行われると、Mac OS は指定された Pascal 文字列を HFSUniStr255 に変換します。 このとき、ソーステキストのエンコーディングはカタログレコードの textEncoding フィールドに格納されます。 そのレコードに対応する Pascal 文字列を作成する必要があると、Mac OS はテキスト変換処理のヒントとして textEncoding を使用します。 このヒントにより忠実度の高い双方向の変換が実現され、結果として互換性も向上します。
|
HFS Plus のテキストエンコーディングを支援する第 2 の機能はボリュームヘッダーの encodingsBitmap フィールドです。 ボリューム上のカタログノードで使用される各エンコーディングに対して、encodingsBitmap フィールドの対応するビットがセットされていなければなりません。
逆に、ボリューム上のどの名前にも特定のエンコーディングが使用されていないときに、そのエンコーディングに対応するビットがビットマップの中でセットされていても構いません。 これは、インプリメンテーションがオブジェクトの削除または名前変更を行うとき、それが特定のエンコーディングを使用する最後の名前であった場合にも、そのエンコーディングビットをクリアする必要がないということを意味します。
|
重要:
テキストエンコーディング値は、ボリューム上で使用されているエンコーディングを示すために、encodingsBitmap フィールドにセットするビットの番号として使用されます。 ただし、encodingsBitmap は 64 ビット長しかないため、MacFarsi および MacUkrainian に対応するテキストエンコーディング値はビット番号として使用できません。 このため、別のビット番号(カッコ内に示しました)が使用されます。
|
|
注意:
Mac OS は encodingsBitmap フィールドに基づいて、ボリュームがマウントされるときにロードするテキストエンコーディング変換テーブルを決定します。 テキストエンコーディング変換テーブルはサイズが大きく、テーブルを不必要にロードするとメモリの浪費になります。 大部分のシステムでは 1 つのテキストエンコーディングのみを使用するため、必要なエンコーディングをボリューム単位で記録することには大きなメリットがあります。
|
|
警告:
HFS Plus の非 Mac OS インプリメンテーションでは encodingsBitmap フィールドを正しく維持する必要があります。 特に、インプリメンテーションにおいてカタログレコードの textEncoding フィールドにテキストエンコーディング値を設定する場合は、encodingsBitmap フィールドの対応するビットも確実にセットする必要があります。これにより、Mac OS を実行するシステムでディスクがマウントされるときに正しい動作が保証されます。
|
HFS Plus の日付
HFS Plus は日付をボリュームヘッダーやカタログレコードなどのいくつかのデータ構造に格納します。 これらの日付は、1904 年 1 月 1 日(GMT)の午前 0 時から経過した秒数を含んだ符号なし 32 ビット整数(UInt32)として格納されます。 この点は、値が地方時を表す HFS と若干異なります。
表現可能な最大の日付は 2040 年 2 月 6 日の 6 時 28 分 15 秒(GMT)です。
この日付値はうるう秒が計算に入っていません。 その代わりに、毎年、4 等分したうるう日が日付に組み込まれます。 表現可能な日付の範囲に、うるう日を持たない 1900 年または 2100 年が含まれていないので、これでも十分役割を果たします。
クライアントソフトウェアが想定しているフォーマットへの日付と時刻の変換は、それぞれのインプリメンテーションに任されています。 たとえば、Mac OS の File Manager は日付を地方時で渡します。そして、Mac OS HFS Plus のインプリメンテーションはその地方時と GMT との間で日付の変換を適切に行います。
|
注意:
ボリュームヘッダーに格納される作成日は GMT で格納されません。作成日は地方時で格納されます。 これは、多くのアプリケーション(バックアップユーティリティを含む)がボリュームの作成日を比較的一意の識別子として使用しているためです。 日付が GMT で格納されていて、インプリメンテーション(Mac OS のような)によって自動的に地方時に変換されてしまうと、地方時のゾーンや夏時間の設定が変わると、その値が変わったように見えることになります (その結果、一部のアプリケーションはボリュームを適切に識別できなくなる可能性があります)。 ボリュームの作成日を一意の識別子として使用することは、それを日付として使用することよりも優先されます。 この変更は Mac OS 8.1プロジェクトの最後の段階で導入されました。
|
HFS Plus のアクセス権
それぞれのファイルやフォルダについて、HFS Plus は HFSPlusBSDInfo 構造体によって定義されたアクセス権を含むレコードを保持します。
struct HFSPlusBSDInfo {
UInt32 ownerID;
UInt32 groupID;
UInt8 adminFlags;
UInt8 ownerFlags;
UInt16 fileMode;
union {
UInt32 iNodeNum;
UInt32 linkCount;
UInt32 rawDevice;
} special;
};
typedef struct HFSPlusBSDInfo HFSPlusBSDInfo;
|
それぞれのフィールドは次のような意味を持ちます。
ownerID- ファイルまたはフォルダの所有者の Mac OS X ユーザ ID。 バージョン 10.3 以前の Mac OS X では、ユーザ ID 99 は、現在コンソールにログインしているユーザの ID として扱われます。 コンソールにログインしているユーザがいなければ、ユーザ ID 99 はユーザ ID 0(root)として扱われます。 Mac OS X バージョン 10.3 では、ユーザ ID 99 は、呼び出しを行っているユーザの ID として扱われます(その結果、同時に全員が所有者となります)。 これらの置き換えは実行時に行われます。 ディスク上の実際のユーザ ID は変わりません。
groupID- ファイルまたはフォルダに関連付けられているグループの Mac OS X グループ ID。 通常、Mac OS X では、グループ ID 99 は「unknown」という名前のグループに割り当てられます。 Mac OS X では、実行時のグループ ID の置き換えはありません。
adminFlags- スーパーユーザのみが設定可能な BSD フラグ群。 このフィールドは、Mac OS X の
struct stat の st_flags フィールドの 16 ビット目から 23 ビット目までに対応します。 詳細については、chflags(2) のマニュアルページを参照してください。 次の表は、adminFlags フィールド内のビット位置と、st_flags フィールドで使用される対応するマスクの名前を示します。
| ビット | st_flags のマスク | 意味 |
|---|
| 0 | SF_ARCHIVED | ファイルはアーカイブ済み |
| 1 | SF_IMMUTABLE | ファイルは変更不可 |
| 2 | SF_APPEND | ファイルへの書き込みは追加のみ可 |
ownerFlags- ファイルまたはディレクトリの所有者またはスーパーユーザが設定可能な BSD フラグ群。 このフィールドは、Mac OS X の
struct stat の st_flags フィールドの 0 ビット目から 7 ビット目までに対応します。 詳細については、chflags(2) のマニュアルページを参照してください。 次の表は、ownerFlags フィールド内のビット位置と、st_flags フィールドで使用される対応するマスクの名前を示します。
| ビット | st_flags のマスク | 意味 |
|---|
| 0 | UF_NODUMP | このファイルをダンプ(バックアップまたはアーカイブ)しない |
| 1 | UF_IMMUTABLE | ファイルは変更不可 |
| 2 | UF_APPEND | ファイルへの書き込みは追加のみ可 |
| 3 | UF_OPAQUE | ディレクトリは不透過(後述を参照) |
fileMode- BSD のファイルタイプとモードビット群。 以下に示すヘッダーから抜粋した定数は、16 進数ではなく 8 進数である点に注意してください。
#define S_ISUID 0004000 /* 実行時にユーザ ID をセット */
#define S_ISGID 0002000 /* 実行時にグループ ID をセット */
#define S_ISTXT 0001000 /* スティッキービット */
#define S_IRWXU 0000700 /* 所有者の RWX マスク */
#define S_IRUSR 0000400 /* 所有者の R マスク */
#define S_IWUSR 0000200 /* 所有者の W マスク */
#define S_IXUSR 0000100 /* 所有者の X マスク */
#define S_IRWXG 0000070 /* グループの RWX マスク */
#define S_IRGRP 0000040 /* グループの R マスク */
#define S_IWGRP 0000020 /* グループの W マスク */
#define S_IXGRP 0000010 /* グループの X マスク */
#define S_IRWXO 0000007 /* その他のユーザの RWX マスク */
#define S_IROTH 0000004 /* その他のユーザの R マスク */
#define S_IWOTH 0000002 /* その他のユーザの W マスク */
#define S_IXOTH 0000001 /* その他のユーザの X マスク */
#define S_IFMT 0170000 /* ファイルマスクのタイプ */
#define S_IFIFO 0010000 /* 名前付きパイプ(fifo) */
#define S_IFCHR 0020000 /* キャラクタ特殊 */
#define S_IFDIR 0040000 /* ディレクトリ */
#define S_IFBLK 0060000 /* ブロック特殊 */
#define S_IFREG 0100000 /* 通常 */
#define S_IFLNK 0120000 /* シンボリックリンク */
#define S_IFSOCK 0140000 /* ソケット */
#define S_IFWHT 0160000 /* ホワイトアウト */
|
UNIX のいくつかのバージョンでは、スティッキービットの S_ISTXT を使用して、実行可能ファイルの終了後もファイルのコードをメモリ内に残すことを示します。これは、同じ実行可能ファイルがまたすぐに使用される場合にパフォーマンスの向上に寄与します。 Mac OS X はこの最適化機能を使用しません。 ディレクトリのスティッキービットがセットされている場合、Mac OS X では、当該ディレクトリ内のファイルの移動、削除、名前の変更を制限します。 ファイルは、削除を行うユーザがファイルが格納されているディレクトリに対する書き込み権限があり、ファイルまたはディレクトリの所有者である場合、またはスーパーユーザである場合に削除できます。
special- このフィールドは、特別な種類のファイルの場合にのみ使用されます。 ディレクトリおよび大半のファイルではこのフィールドは使用されず、予約済みです。 使用されている場合、このフィールドは次のいずれかとして使用されます。
iNodeNum- ハードリンクファイルの場合、このフィールドにはリンク参照番号が格納されます。 詳細については、「ハードリンク」のセクションを参照してください。
linkCount- 間接ノードファイルの場合、このフィールドには当該ノードファイルを指すハードリンクの数が格納されます。 詳細については、「ハードリンク」のセクションを参照してください。
rawDevice- ブロック型特殊デバイスファイルおよびキャラクタ型特殊デバイスファイルの場合(
S_IFMT フィールドに S_IFCHR または S_IFBLK が格納されている場合)、このフィールドにはデバイス番号が格納されます。
|
警告:
Mac OS 8 および 9 では、アクセス権は予約済みとして扱われます。
|
|
注意:
S_IFWHT および UF_OPAQUE の値は、ファイルシステムが union マウントの一部としてマウントされている場合に使用されます。 union マウントは複数のファイルシステムを統合して単独のファイルシステムとして使用するマウントの方法です。 概念上、これらのファイルシステムは相互に重なった階層を形成します。 ファイルまたはディレクトリが複数の階層に存在する場合、最上位層のものが使用されます。 すべての変更は最上位のファイルシステムにのみ適用され、他のファイルシステムは読み取り専用となります。 最上位以外の層にあるファイルまたはディレクトリを削除するために、最上位層にはホワイトアウトエントリ(ファイルタイプは S_IFWHT)が作成されます。 最上位層以外の層のディレクトリが削除された後に再度作成された場合、下位の層における当該ディレクトリの内容は、最上位層のディレクトリに UF_OPAQUE フラグをセットすることで隠す必要があります。 S_IFWHT と UF_OPAQUE はともに、下位の層にある対応する名前を隠します。これは、union マウントが下位の層の同名のファイルまたはディレクトリにアクセスできないようにすることで実現されます。
|
|
注意:
fileMode フィールドの S_IFMT フィールド(上位 4 ビット)がゼロの場合、Mac OS X はアクセス権造体が初期化されていないとみなし、内部的にすべてのフィールドについてデフォルト値を使用します。 デフォルトのユーザ ID とグループ ID は 99 ですが、ボリュームのマウント時に変更することが可能です。 その場合、デフォルトの ownerID は前述の説明に従って置き換えられます。
したがって、Mac OS 8 および 9、あるいはアクセス権フィールドをゼロに設定する任意のインプリメンテーションで作成されたファイルは、ボリューム全体で「所有権無視」が無効になっていても、「所有権無視」のオプションが有効になっているかのように振る舞います。
|
フォークデータ構造体
HFS Plus は HFSPlusForkData 構造体を使ってファイルの内容に関する情報を保持します。 このような構造体が 2 つ(1 つはリソースフォークに対応するもので、もう 1 つはデータフォークに対応するもの)が各ユーザファイルに対するカタログレコードに格納されています。 また、ボリュームヘッダーには、それぞれの特殊ファイルに対するフォークデータ構造体が含まれます。
エクステントレコードに含まれる未使用のエクステント記述子は、startBlock および blockCount の両方がゼロに設定されます。 たとえば、対象となるフォークが 3 つのエクステントを占有している場合、最後の 5 つのエクステント記述子はすべてゼロになります。
struct HFSPlusForkData {
UInt64 logicalSize;
UInt32 clumpSize;
UInt32 totalBlocks;
HFSPlusExtentRecord extents;
};
typedef struct HFSPlusForkData HFSPlusForkData;
typedef HFSPlusExtentDescriptor HFSPlusExtentRecord[8];
|
それぞれのフィールドは次のような意味を持ちます。
logicalSize- フォークに含まれる有効なデータのサイズ(バイト単位)。
clumpSize- ボリュームヘッダーに含まれる
HFSPlusForkData 構造体においては、これはフォークのクランプサイズです。このサイズは、ボリュームヘッダー内のデフォルトのクランプサイズに優先して使用されます。
カタログレコードに含まれる HFSPlusForkData 構造体においては、このフィールドはボリュームヘッダー内のデフォルトのクランプサイズに優先するフォークごとのクランプサイズを格納することを目的としていました。 しかし、Mac OS X バージョン 10.3 以前のアップルのインプリメンテーションではこのフィールドを無視していました。 Mac OS X バージョン 10.3 からは、このフィールドはフォークから実際に読み取ったブロックの数を記録するために使用されています。 詳細については、「ホットファイル」のセクションを参照してください。
totalBlocks- 対象となるフォークのすべてのエクステントで使用されるアロケーションブロックの総数。
extents- フォークのエクステント記述子の配列。 この配列には、先頭から 8 つのエクステント記述子が保持されます。 それを超えるエクステント記述子が必要な場合、それらはエクステントオーバーフローファイルに格納されます。
HFSPlusExtentDescriptor 構造体は個々のエクステントに関する情報を保持するために使用されます。
struct HFSPlusExtentDescriptor {
UInt32 startBlock;
UInt32 blockCount;
};
typedef struct HFSPlusExtentDescriptor HFSPlusExtentDescriptor;
|
それぞれのフィールドは次のような意味を持ちます。
startBlock- エクステント内の先頭のアロケーションブロック。
blockCount- アロケーションブロック単位で表したエクステントの長さ。
先頭に戻る
ボリュームヘッダー
各 HFS Plus ボリュームには、ボリュームの先頭から 1024 バイトの位置にボリュームヘッダーがあります。 HFS のマスターディレクトリブロック(MDB)に相当するボリュームヘッダーには、ボリューム内のその他の重要な構造の位置など、ボリューム全体に関する情報が含まれます。 インプリメンテーションでは、ボリュームがアンマウントされる前に必ずこの構造を更新する必要があります。
ボリュームヘッダーのコピーである代替ボリュームヘッダーは、ボリュームの末尾から 1024 バイトさかのぼった位置から始まる場所に格納されています。 インプリメンテーションでは、いずれかの特殊ファイルの長さまたは場所が変更されたときにだけこのコピーを更新する必要があります。 代替ボリュームヘッダーは、もっぱらディスク修復ユーティリティで使用することを前提にしています。
ボリュームの最初の 1024 バイトおよび最後の 512 バイトは予約されています。
|
注意:
最初の 1024 バイトはブートブロックとして使用するために予約されています。従来の Mac OS の Finder は、システムフォルダが変更されたときにこれらのセクタへの書き込みを行います。 ブートブロックのフォーマットはこの仕様の対象範囲外です。 このフォーマットは「Inside Macintosh: Files」で定義されています。
最後の 512 バイトは、アップルの CPU 製造工程で使用されます。
|
最初の 1536 バイト(予約済みにボリュームヘッダーを加えた量)を含むアロケーションブロック(1 つまたは複数)は、アロケーションファイルの中で「使用済み」としてマークされています(詳細については、「アロケーションファイル」のセクションを参照してください)。 また、代替ボリュームヘッダーとそれに続く予約済みの領域に対応するために、最後のアロケーションブロック(または、ボリュームが 512 バイト単位のアロケーションブロックを使用してフォーマットされている場合には 2 つのアロケーションブロック)もアロケーションファイルにおいて使用中として印がつけられます。
|
重要:
代替ボリュームヘッダーは、必ずボリュームの末尾から 1024 バイトの位置に格納されています。 ディスクのサイズが、アロケーションブロックサイズの偶数倍でない場合、この領域は最後のアロケーションブロックの境界を越える場合があります。 しかし、代替ボリュームヘッダーがそこに格納されていない場合でも、最後のアロケーションブロック(または、512 バイト単位のアロケーションブロックでフォーマットされているボリュームでは 2 つのアロケーションブロック)は予約済みとなります。
|
ボリュームヘッダーは HFSPlusVolumeHeader 型によって記述されます。
struct HFSPlusVolumeHeader {
UInt16 signature;
UInt16 version;
UInt32 attributes;
UInt32 lastMountedVersion;
UInt32 journalInfoBlock;
UInt32 createDate;
UInt32 modifyDate;
UInt32 backupDate;
UInt32 checkedDate;
UInt32 fileCount;
UInt32 folderCount;
UInt32 blockSize;
UInt32 totalBlocks;
UInt32 freeBlocks;
UInt32 nextAllocation;
UInt32 rsrcClumpSize;
UInt32 dataClumpSize;
HFSCatalogNodeID nextCatalogID;
UInt32 writeCount;
UInt64 encodingsBitmap;
UInt32 finderInfo[8];
HFSPlusForkData allocationFile;
HFSPlusForkData extentsFile;
HFSPlusForkData catalogFile;
HFSPlusForkData attributesFile;
HFSPlusForkData startupFile;
};
typedef struct HFSPlusVolumeHeader HFSPlusVolumeHeader;
|
それぞれのフィールドは次のような意味を持ちます。
signature- ボリュームシグネチャ。これは、HFS Plus ボリュームに対しては
kHFSPlusSigWord('H+')、HFSX ボリュームに対しては kHFSXSigWord('HX')でなければなりません。
version- ボリュームフォーマットのバージョン。現在のバージョンは、HFS Plus ボリュームに対しては 4(
kHFSPlusVersion)、HFSX ボリュームに対しては 5(kHFSXVersion)となっています。
attributes- 後述するボリューム属性。
lastMountedVersion- 書き込みを行うためにこのボリュームを最後にマウントしたインプリメンテーションを一意に識別する値。 この値は、将来のインプリメンテーションにおいて、古いインプリメンテーションによって最後にマウントされたボリュームを検出して、問題がないかどうかをチェックするために使用できます。 オンディスク構造に変更を加えるコードは、このフィールドにコードを識別する一意の値にセットする必要もあります。 サードパーティによる HFS Plus のインプリメンテーションでは、このフィールドに登録されているクリエータコードを格納してください。 Mac OS 8.1から 9.2.2 にかけて使用されている値は
'8.10' です。 Mac OS X によって使用される値は '10.0' です。 Mac OS X において、ジャーナルボリューム(HFSX を含む)によって使用される値は 'HFSJ' です。 Mac OS X 上で fsck_hfs によって使用される値は 'fsck' です。
|
注意:
lastMountedVersion をセットすることは、インプリメンテーション(およびボリュームに直接変更を加えるユーティリティ)にとって非常に重要です。 また、インプリメンテーションまたはユーティリティに大きな変更が加えられたときに異なる値を選択することも重要です。 インプリメンテーションまたはユーティリティにバグが発見されても、lastMountedVersion が正しくセットされていれば、他のインプリメンテーションやユーティリティが何らかの問題を検出して訂正することはかなり容易なはずです。
|
journalInfoBlock- ボリュームのジャーナルに対する
JournalInfoBlock が格納されいているアロケーションブロックのアロケーションブロック番号。 このフィールドは、attribute フィールドの kHFSVolumeJournaledBit がセットされている場合にのみ有効です。それ以外の場合、このフィールドは予約済みとなります。
createDate- ボリュームが作成された日付と時刻。 フォーマットの詳細については、「HFS Plus の日付」を参照してください。
modifyDate- ボリュームが最後に修正された日付と時刻。 フォーマットの詳細については、「HFS Plus の日付」を参照してください。
backupDate- ボリュームが最後にバックアップされた日付と時刻。 ボリュームフォーマットにおいては、このフィールドに対して特に何もする必要はありません。このフィールドは、ユーザプログラムの便宜を図る目的でのみ定義されています。 フォーマットの詳細については、「HFS Plus の日付」を参照してください。
checkedDate- ボリュームの一貫性が最後にチェックされた日付と時刻。 Disk First Aid などのディスクチェックツールでは、ディスクチェックを実行したときにこのフィールドをセットする必要があります。 ディスクチェックツールは、この日付に基づいて、定期的なボリュームのチェックを実行することが可能です。
fileCount- ボリューム上にあるファイルの総数。
fileCount フィールドの値に特殊ファイルは含まれません。 この値は、カタログファイルに記録されているファイルレコードの数と同じはずです。
folderCount- ボリューム上にあるフォルダの総数。
folderCount フィールドの値にはルートフォルダは含まれません。 この値は、カタログファイルに記録されているフォルダレコードの数から 1 を引いた数と同じはずです(カタログファイルのフォルダレコードにはルートフォルダも含まれているため)。
blockSize- アロケーションブロックサイズ(バイト単位)。
totalBlocks- ディスク上にあるアロケーションブロックの総数。 サイズがアロケーションブロックサイズの偶数倍であるディスクの場合、ボリュームヘッダーと代替ボリュームヘッダーを含めて、ディスク上のすべての領域がアロケーションブロックに組み込まれます。 ディスクのサイズが、アロケーションブロックサイズの偶数倍でない場合、全体がディスクに収まるアロケーションブロックのみが数えられます。 ディスク末尾の残余領域はボリュームフォーマットでは使用されません(前述のように、代替ボリュームヘッダーの格納に使用する場合を除きます)。
freeBlocks- ディスク上にある未使用のアロケーションブロックの総数。
nextAllocation- 次のアロケーション検索の開始点。
nextAllocation フィールドは、ファイルの領域を割り当てるときに空きアロケーションブロックの検索を開始する場所のヒントとして Mac OS によって使用されます。 このフィールドには、検索を開始することになるアロケーションブロック番号が含まれます。 この種のヒントを必要としないインプリメンテーションでは、このフィールドを予約済みとして扱うこともできます。 [インプリメンテーション詳細: 従来の Mac OS のインプリメンテーションでは、通常、このフィールドに最も最近割り当てられたエクステントの先頭のアロケーションブロックをセットしていました。 最も最近割り当てられたエクステントの直後にあるアロケーションブロックがこのフィールドにセットされることはありません。というのも、ファイルがクローズされるときにそのエクステントが短縮される可能性があるためです(クランプ全体が割り当てられていても、実際に使用されていないこともあるため)。] 詳細については、「アロケーションファイル」のセクションを参照してください。
rsrcClumpSize- リソースフォークのデフォルトのクランプサイズ(バイト単位)。 これは、サイズが大きくなっているファイルをどこまで拡張するかをインプリメンテーションに対して示すヒントとなります。 現在までのアップルのインプリメンテーションは、データフォークとリソースフォークのどちらについても、
rsrcClumpSize を無視し、dataClumpSize を使用します。
dataClumpSize- データフォークのデフォルトのクランプサイズ(バイト単位)。 これは、サイズが大きくなっているファイルをどこまで拡張するかをインプリメンテーションに対して示すヒントとなります。 現在までのアップルのインプリメンテーションは、データフォークとリソースフォークのどちらについても、
rsrcClumpSize を無視し、dataClumpSize を使用します。
nextCatalogID- 使用されていない次のカタログ ID。 カタログ ID の詳細については、「カタログファイル」を参照してください。
writeCount- このフィールドはボリュームがマウントされるたびに増加していきます。 このフィールドを使用することで、インプリメンテーションはメディアが取り出された(あるいは何らかの理由でアクセスできない)場合でも、ボリュームをマウントし続けることができます。 メディアが再度挿入されたとき、インプリメンテーションはこのフィールドをチェックして、取り出されていた間にメディアが変更されたかどうかを判断できます。 ボリュームの構造を直接的に変更した場合、インプリメンテーションまたはユーティリティは
writeCount フィールドを変更する必要があります。 このことは、ボリューム上の項目を追加または削除した場合には特に重要になります。
encodingsBitmap- このフィールドは、ボリューム上のファイルおよびフォルダの名前に使用されているテキストエンコーディングを追跡します。 このビットマップにより、Unicode 名を直接的に使用しないインプリメンテーションのパフォーマンスを部分的に最適化することができます。 詳細については、「テキストエンコーディング」のセクションを参照してください。
finderInfo-
32 ビットの項目で構成されるこの配列には、Mac OS の Finder およびシステムソフトウェアのブートプロセスによって使用される情報が格納されています。
finderInfo[0] には、ブート可能システムが格納されているディレクトリ(Mac OS 8 または 9 における「システムフォルダ」、あるいは、Mac OS X における /System/Library/CoreServices など)のディレクトリ ID が格納されています。 ボリューム上にブート可能なシステムがない場合にはゼロとなります。 この値は通常、finderInfo[3] または finderInfo[5] と同じです。
finderInfo[1] には、スタートアップアプリケーション(Finder など)の親ディレクトリの ID、または、ボリュームがブート可能でない場合はゼロが格納されています。
finderInfo[2] には、ボリュームがマウントされたときに Finder に表示するディレクトリのディレクトリ ID、または、ディレクトリウィンドウを開かない場合にはゼロが格納されています。 従来の Mac OS では、このウィンドウは、開く対象となるウィンドウのリンクリストの最初のウィンドウです。ディレクトリの Finder 情報の frOpenChain フィールドに、リスト内の次のディレクトリの ID が格納されています。 オープンウィンドウリストは使用が廃止されました。 Mac OS X の Finder はこのディレクトリのウィンドウを開きますが、オープンウィンドウリストの残りは無視します。 Mac OS X の Finder はこのフィールドを変更しません。
finderInfo[3] には、ブート可能な Mac OS 8 または 9 の「システムフォルダ」のディレクトリ ID、または、なければゼロが格納されています。
finderInfo[4] は予約済みです。
finderInfo[5] には、ブート可能な Mac OS X システム(/System/Library/CoreServices ディレクトリ)のディレクトリ ID、または、ボリューム上にブート可能な Mac OS X システムがなければゼロが格納されています。
finderInfo[6] および finderInfo[7] は、64 ビットの一意のボリューム識別子を格納するために Mac OS X によって使用されます。 この識別子の 1 つの使い方は、ボリュームの所有権(ユーザ ID)情報を尊重するかどうかを追跡することです。 これらの要素は、ボリュームに対して識別子が作成されていなければゼロとなります。
allocationFile- アロケーションファイルの位置とサイズに関する情報。
HFSPlusForkData 型の詳細については、「フォークデータ構造体」を参照してください。
extentsFile- エクステントファイルの位置とサイズに関する情報。
HFSPlusForkData 型の詳細については、「フォークデータ構造体」を参照してください。
catalogFile- カタログファイルの位置とサイズに関する情報。
HFSPlusForkData 型の詳細については、「フォークデータ構造体」を参照してください。
attributesFile- アトリビュートファイルの位置とサイズに関する情報。
HFSPlusForkData 型の詳細については、「フォークデータ構造体」を参照してください。
startupFile- スタートアップファイルの位置とサイズに関する情報。
HFSPlusForkData 型の詳細については、「フォークデータ構造体」を参照してください。
ボリューム属性
ボリュームヘッダーの attributes フィールドは 1 ビットフラグの集合として扱われます。 各ビットの定義は以下に示す定数によって与えられます。
enum {
/* ビット 0〜6 は予約されている */
kHFSVolumeHardwareLockBit = 7,
kHFSVolumeUnmountedBit = 8,
kHFSVolumeSparedBlocksBit = 9,
kHFSVolumeNoCacheRequiredBit = 10,
kHFSBootVolumeInconsistentBit = 11,
kHFSCatalogNodeIDsReusedBit = 12,
kHFSVolumeJournaledBit = 13,
/* ビット 14 は予約されている */
kHFSVolumeSoftwareLockBit = 15
/* ビット 16〜31 は予約されている */
};
|
それぞれのビットは次のような意味を持ちます。
- ビット 0-7
- インプリメンテーションでは、これらのビットを予約済みとして扱う必要があります。
kHFSVolumeUnmountedBit(ビット 8)- このビットは、アンマウントまたは取り出しの前にボリュームが正しくフラッシュされた場合にセットします。 インプリメンテーションでは、書き込みを行うためにボリュームをマウントするとき、メディア上のこのビットをクリアする必要があります。 また、他のすべてのボリューム情報をフラッシュした後で、書き込み可能ボリュームをアンマウントする最後のステップとして、メディア上のこのビットをセットする必要があります。 このビットがクリアされているボリュームのマウントを要求された場合、インプリメンテーションはそのボリュームの一貫性に問題があるとみなし、そのボリュームを使用する前に適切な一貫性チェックを実行しなければなりません。
kHFSVolumeSparedBlocksBit(ビット 9)- このビットは、エクステントオーバーフローファイルの中に不良ブロック(ファイル ID
IDkHFSBadBlockFileID に属する)に関する何らかのレコードが含まれている場合にセットします。 詳細については、「不良ブロックファイル」を参照してください。
kHFSVolumeNoCacheRequiredBit(ビット 10)- このビットは、このボリュームのブロックのキャッシュを行う必要がない場合にセットします。 たとえば、RAM または ROM ディスクは実際にはメモリ内に格納されているので、ボリュームの内容をキャッシュするために追加のメモリを使用するのは無駄です。
kHFSBootVolumeInconsistentBit(ビット 11)- このビットは
kHFSVolumeUnmountedBit に似ていますが、意味が逆になります。 インプリメンテーションでは、書き込みを行うためにボリュームをマウントするとき、メディア上のこのビットをセットする必要があります。 また、他のすべてのボリューム情報をフラッシュした後で、書き込み可能ボリュームをアンマウントする最後のステップとして、メディア上のこのビットをクリアする必要があります。 このビットがセットされているボリュームのマウントを要求された場合、インプリメンテーションはそのボリュームの一貫性に問題があるとみなし、そのボリュームを使用する前に適切な一貫性チェックを実行しなければなりません。
kHFSCatalogNodeIDsReusedBit(ビット 12)- このビットは、
nextCatalogID フィールドが 32 ビットを超え、より小さなカタログノード ID を再利用する必要がある場合にセットします。 このビットがセットされている場合、nextCatalogID と同じまたはそれよりも大きい ID を持つカタログレコードが存在するのが一般的です(エラーではありません)。 このビットがセットされている場合、新規作成されるカタログレコードに割り当てる ID が既存のレコードで使用されている ID と重複しないようにする必要があります。
kHFSVolumeJournaledBit(ビット 13)- このビットがセットされている場合、当該ボリュームにはジャーナルがあります。ジャーナルは、ボリュームヘッダーの
journalInfoBlock フィールドを使用して場所を知ることができます。
- 第 14 ビット
- インプリメンテーションでは、このビットを予約済みとして扱う必要があります。
kHFSVolumeSoftwareLockBit(ビット 15)- このビットは、ソフトウェアの設定によってボリュームが書き込み保護されている場合にセットされます。 このビットがセットされている場合、インプリメンテーションではボリュームへの書き込みを拒否する必要があります。 このフラグは、他の方法では書き込み禁止にできないメディア上のボリュームを保護したり、パーティションに分割されたデバイス上の個別のパーティションを保護するときに特に役立ちます。
- 第 16 〜 31 ビット
- インプリメンテーションでは、これらのビットを予約済みとして扱う必要があります。
|
注意:
Mac OS X バージョン 10.0 から 10.3 までは、kHFSVolumeSoftwareLockBit を正しく尊重しません。 それらのバージョンでは誤ってボリュームの変更が許可されます。 このバグは、Mac OS X の将来のバージョンで修正される予定です(r. 3507614)。
|
|
注意:
インプリメンテーションは、属性のコピーをメモリ内に保持し、そのビット 0 からビット 7 までを独自のラインタイムフラグとして使用することができます。 たとえば、Mac OS はビット 7(kHFSVolumeHardwareLockBit)を使って、何らかのハードウェア設定によってボリュームが書き込み禁止になっていることを示します。
|
|
注意:
2 つのボリューム一貫性ビット(kHFSVolumeUnmountedBit および kHFSBootVolumeInconsistentBit)が存在することには若干の説明が必要です。 kHFSVolumeUnmountedBit がクリアされていると、Macintosh の ROM はブートボリュームの一貫性をチェックします。 ROM ベースのチェックは非常に時間がかかり、ユーザのフラストレーションを高めます。 このチェックを行うコードは Mac OS 7.6 で大幅に最適化されました。 ROM チェックが使用されないように、Mac OS 7.6 以降ではオリジナルの一貫性チェックビット(kHFSVolumeUnmountedBit)は常時セットされたままになっています。 その代わりに、ディスクの一貫性チェックを行う必要があることを示すシグナルとして代替のフラグ(kHFSBootVolumeInconsistentBit)が使用されます。
|
|
注意:
ブートボリュームの場合、kHFSBootVolumeInconsistentBit は説明したとおりに使用する必要がありますが、kHFSVolumeUnmountedBit は常にセットされていなければなりません。その他すべてのボリュームの場合、kHFSVolumeUnmountedBit を説明したとおりに使用し、kHFSBootVolumeInconsistentBit は常にクリアしておきます。 この最適化により、ブートボリュームがマウントされるときに Mac OS の ROM が kHFSVolumeUnmountedBit をチェックするだけで、一貫性チェックを行わないので、非常に時間のかかる一貫性チェックを避けることができます。File Manager はその後で kHFSBootVolumeInconsistentBit がセットされているかどうかを見て、より高速で快適な一貫性チェックを行います (Mac OS のブートに時間がかかるようになりますが、常に両方のビットを使用してもかまいません)。
|
先頭に戻る
B ツリー
|
注意:
B ツリーの保守に使用するアルゴリズムの実際的な説明については、『Algorithms in C』、Robert Sedgewick 著、Addison-Wesley 刊、1992 年発行(ISBN: 0201514257)を参照してください。
多くの教科書の B ツリーの説明にしたがえば、B ツリー内のインデックスノードには、N 個のキーと N+1 個のポインタが含まれています。そして、キー番号が X 未満のキーはポインタ番号 X によってポイントされるサブツリー内にあり、キー番号が X を超えるキーはポインタ番号 X+1 によってポイントされるサブツリー内にあります (同一のキーに対してポインタ番号 X と X+1 のどちらを使用するかは、B ツリーをインプリメントするデベロッパが定義します)。
HFS と HFS Plus はこれが若干異なります。つまり、サブツリー内に、当該サブツリーのルートノードの先頭キーより小さいキーが存在しません。
|
このセクションでは、カタログファイル、エクステントオーバーフローファイル、およびアトリビュートファイルに使用されている B ツリーの構造について説明します。 B ツリーはファイルのデータフォークに格納されています。 それぞれの B ツリーは、ボリュームヘッダーの中に、そのデータフォークのサイズとエクステントの初期値を記述する HFSPlusForkData 構造体を持ちます。
|
注意:
ボリュームヘッダー内にリソースフォークの HFSPlusForkData を格納する場所が用意されていないため、特殊ファイルにはリソースフォークがありません。 また、データフォークはエクステントオーバーフローファイルに B ツリーのエクステントを格納するために使用するキーの一部であるため、B ツリーがデータフォーク内に格納されていることは重要です。
|
B ツリーファイルは複数の固定長ノードに分割されます。それぞれのノードには複数のレコードが含まれ、それらのレコードは 1 つのキーといくらかのデータで構成されます。 B ツリーの目的は、あるキーをそれに対応するデータに効率的にマップすることです。 これを実現するためは、キーに何らかの順列がなければなりません。つまり、あるキーを別のキーと比較して、小さいか、等しいか、大きいかを判定できる厳密に定義された方法が存在する必要があるということです。
ノードのサイズ(バイト単位で表される)は、512 から 32,768 までの範囲の 2 のべき乗値でなければなりません。 B ツリーのノードサイズは、B ツリーの作成時に決まります。 B ツリーファイルの論理長は、ノードの数とノードサイズを掛け合わせた値になります。
次のような 4 種類のノードがあります。
- それぞれの B ツリーには 1 つのヘッダーノードが含まれています。 ヘッダーノードは常に B ツリー内の先頭ノードです。 このノードには、ツリー内の他のノードを検索するときに必要な情報が含まれています。
- マップノードにはマップレコードが含まれます。マップレコードには、ヘッダーノードのマップレコードに収まりきらないアロケーションデータ(B ツリー内の空きノードを示すビットマップ)が格納されます。
- インデックスノードには B ツリーの構造を定義するポインタレコードが含まれます。
- リーフノードには、キーに関連付けられているデータを含むデータレコードが格納されます。 各データレコードに対応するキーは一意でなければなりません。
すべてのノードは、次のセクションで説明する共通の構造を持っています。
ノードの構造
ノードは番号によって指定されます。 ノードの番号は、そのノードのファイル内でのオフセット値をノードサイズで割って求めることができます。 それぞれのノードは同一の一般構造を持ちます。つまり、1 つのノードは、ノードの先頭にあるノード記述子、ノードの最後にあるレコードオフセットのリスト、およびレコードのリストという 3 つの主要部分から構成されます。 図 2 に、この構造を示します。

図 2. ノードの構造
ノード記述子には、ノードに関する基本的な情報と、他のノードとの相互リンクが含まれます。 BTNodeDescriptor データ型がこの構造を表します。
struct BTNodeDescriptor {
UInt32 fLink;
UInt32 bLink;
SInt8 kind;
UInt8 height;
UInt16 numRecords;
UInt16 reserved;
};
typedef struct BTNodeDescriptor BTNodeDescriptor;
|
それぞれのフィールドは次のような意味を持ちます。
fLink- 同じタイプの次のノードのノード番号。 最後のノードの場合は 0。
bLink- 同じタイプの前のノードのノード番号。 先頭のノードの場合は 0。
kind- ノードのタイプ。 4 種類のノード(ヘッダーノード、マップノード、インデックスノード、リーフノード)がありますが、詳細については後述します。
height- B ツリーの階層内での対象となるノードのレベルまたは深さ。 ヘッダーノードの場合、このフィールドはゼロでなければなりません。 リーフノードの場合、このフィールドは 1 でなければなりません。 インデックスノードの場合、このフィールドはそれがポイントする子ノードのレベルよりも 1 大きくなります。 マップノードのレベルはヘッダーノードと同様にゼロになります (マップノードはヘッダーノード内のマップレコードを拡張したものと考えてください)。
numRecords- 対象となるノードに含まれるレコードの数。
reserved- インプリメンテーションでは、これを予約済みのフィールドとして扱う必要があります。
ノード記述子は常に 14 バイト(sizeof(BTNodeDescriptor))の長さを持ちます。このため、ノードに含まれるレコードのリストは、常にノードの先頭から 14 バイト目から始まります。 各レコードのサイズはレコードのタイプとそれに含まれる情報の量によって変わります。
それぞれのレコードは、ノードの末尾にあるレコードのオフセットのリストを使ってアクセスされます。 このリストの各エントリは、ノードの先頭からレコードの先頭までのオフセット値(バイト単位)を含む UInt16 型の値です。 それぞれのオフセットは逆順に格納されています。つまり、先頭のレコードのオフセットはノードの最後の 2 バイトに格納され、2 番目のレコードのオフセットはその前の 2 バイトに格納されます。 先頭のレコードのオフセットは常に 14 であるため、ノードの最後の 2 バイトには 14 という値が含まれることになります。
|
重要:
レコードオフセットのリストには、常にノード内の実際のレコード数よりも 1 つ多いエントリが含まれます。 このエントリにはノード内にある空き領域の先頭バイトのオフセットが含まれており、結果的にノードに含まれる最後のレコードのサイズを示しています。 ノード内に空き領域がない場合、このエントリには、ノードの先頭を起点とするそれ自体のバイトオフセットが含まれます。
|
ノード記述子の kind フィールドはノードのタイプを記述します。これにより、そのノードにどのような種類のレコードが含まれているかがわかり、B ツリーの階層内でのそのノードの目的も明らかになります。 ノードには、次の定数で指定される 4 つのタイプがあります。
enum {
kBTLeafNode = -1,
kBTIndexNode = 0,
kBTHeaderNode = 1,
kBTMapNode = 2
};
|
B ツリーのノードタイプによりそのノードに含まれるレコードのタイプが決まるということを十分に認識しておく必要があります。 リーフノードには常にデータレコードが含まれます。 インデックスノードには常にポインタレコードが含まれます。 マップノードには常にマップレコードが含まれます。 また、ヘッダーレコードには常にヘッダーレコード、予約されているレコード、およびマップレコードが含まれます。 以下のセクションでは、4 つのノードタイプと、それらに対応するレコードについて説明します。
ヘッダーノード
どの B ツリーファイルでも、その先頭ノード(ノード 0)はヘッダーノードです。ヘッダーノードには、B ツリーファイル全体に関する重要情報が含まれます。 ヘッダーレコードの中には 3 つのレコードが存在します。 先頭のレコードは B ツリーヘッダーレコードで、2 番目のレコードは常に 128 バイト長のユーザデータレコードです。 また、最後のレコードは B ツリーマップレコードで、ユーザデータレコードとレコードオフセットの間にある残りの領域すべてを占有します。 図 3 にヘッダーノードの構造を示します。

図 3 ヘッダーノードの構造
ヘッダーノードのノード記述子に含まれる fLink フィールドには、先頭のマップノードのノード番号が含まれます。また、マップノードがない場合は 0 が含まれます。 ヘッダーノードのノード記述子に含まれる bLink フィールドは常にゼロに設定されていなければなりません。
ヘッダーレコード
B ツリーヘッダーレコードには、B ツリーのサイズ、最大のキー長、先頭および最後のリーフノードの位置など、B ツリーに関する一般的な情報が含まれています。 BTHeaderRec データ型がヘッダーレコードの構造を表します。
struct BTHeaderRec {
UInt16 treeDepth;
UInt32 rootNode;
UInt32 leafRecords;
UInt32 firstLeafNode;
UInt32 lastLeafNode;
UInt16 nodeSize;
UInt16 maxKeyLength;
UInt32 totalNodes;
UInt32 freeNodes;
UInt16 reserved1;
UInt32 clumpSize; // misaligned
UInt8 btreeType;
UInt8 keyCompareType;
UInt32 attributes; // long aligned again
UInt32 reserved3[16];
};
typedef struct BTHeaderRec BTHeaderRec;
|
|
注意:
ルートノードがリーフノードであることもあります(この場合、1 つのリーフノードのみが存在し、それゆえインデックスノードは存在しません。このような状況は新規に初期化されたボリューム上のカタログファイルで発生することがあります)。 ツリーにリーフノードがない場合(新規に初期化されたボリューム上のエクステントオーバーフローファイルのように)、firstLeafNode、lastLeafNode、rootNode の各フィールドはすべてゼロになります。 また、リーフノードが 1 つだけ存在する場合(新規に初期化されたボリューム上のカタログファイルでこのような状況が発生する可能性があります)、firstLeafNode、lastLeafNode、rootNode の各フィールドはすべて同じ値(つまり、1 つしか存在しないリーフノードのノード番号)になります。 firstLeafNode および lastLeafNode フィールドを使用すると、fLink/bLink フィールドにしたがうだけですべてのリーフノードを検索することができます。
|
それぞれのフィールドは次のような意味を持ちます。
treeDepth- B ツリーの現在のレベル。 常に、ルートノードの
height フィールドと等しくなります。
rootNode- ルートノード、つまり、B ツリーのルートとして動作するインデックスノードのノード番号。 詳細については、「インデックスノード」を参照してください。
rootNode がリーフノードである可能性もあります。 詳細については、「Inside Macintosh: Files」の 2-69 ページを参照してください。
leafRecords- すべてのリーフノードに含まれるレコードの総数。
firstLeafNode- 先頭にあるリーフノードのノード番号。 リーフノードが存在しない場合、このフィールドの値はゼロになります。
lastLeafNode- 末尾にあるリーフノードのノード番号。 リーフノードが存在しない場合、このフィールドの値はゼロになります。
nodeSize- ノードのサイズ(バイト単位)。 この値は、512 から 32,768 の範囲にある 2 のべき乗値です。
maxKeyLength- インデックスまたはリーフノードに含まれるキーの最大長。 HFSVolumes.h では、HFS および HFS Plus の両方についてカタログファイルとエクステントファイルの
maxKeyLength 値が定義されています(kHFSPlusExtentKeyMaximumLength、kHFSExtentKeyMaximumLength、kHFSPlusCatalogKeyMaximumLength、kHFSCatalogKeyMaximumLength)。 アトリビュート B ツリーの最大キー長はカタログファイルよりも若干大きくなるはずです。 一般に、maxKeyLength は、1 つのノードが最大サイズの 2 つのキーとノード記述子およびオフセットを格納できる程度に十分に小さくなければなりません(nodeSize 比較して)。
totalNodes- B ツリーに含まれるノードの総数(空きノードであるか、使用済みノードであるかに関係なく)。 B ツリーファイルの長さはこの値と
nodeSize を掛け合わせて計算することができます。
freeNodes- B ツリーに含まれる未使用ノードの数。
reserved1- インプリメンテーションでは、これを予約済みのフィールドとして扱う必要があります。
clumpSize- HFS Plus B ツリーでは無視されます。 その代わりに、
HFSPlusForkData レコードの clumpSize フィールドが使用されます。 最大限の互換性を維持するため、インプリメンテーションではノード記述子の clumpSize に、ボリュームを初期化したときの HFSPlusForkData の clumpSize と同じ値を設定してください。 そうでない場合は、ヘッダーレコードの clumpSize を予約済みとして扱ってください。
btreeType- このフィールドに格納される値の型は
BTreeTypes です。
enum BTreeTypes{
kHFSBTreeType = 0, // 制御ファイル
kUserBTreeType = 128, // ユーザ B ツリータイプ、128 から開始
kReservedBTreeType = 255
};
|
このフィールドは、カタログ、エクステント、およびアトリュビュートの各 B ツリーにおいて kHFSBTreeType と同じである必要があります。 このフィールドは、ホットファイル B ツリーにおいて kUserBTreeType と同じである必要があります。 歴史的に、1 〜 127 および kReservedBTreeType の値は、Mac OS 9 およびそれ以前のシステムソフトウェアが使用する B ツリーによって使用されていました。
keyCompareType- HFSX ボリュームでは、カタログ B ツリーヘッダー内のこのフィールドはキーの順列を定義します(ボリュームで大文字小文字が区別されるかどうかにかかわらず)。 それ以外の場合、インプリメンテーションでは、これを予約済みのフィールドとして扱う必要があります。
| 定数名 | 値 | 意味 |
|---|
kHFSCaseFolding | 0xCF | 大小文字統合(大文字小文字を区別しない) |
kHFSBinaryCompare | 0xBC | バイナリ比較(大文字小文字を区別) |
attributes- B ツリーのさまざまな属性を記述するために使用するビットの集合。 これらのビットの意味を以下に示します。
reserved3- インプリメンテーションでは、これを予約済みのフィールドとして扱う必要があります。
次の定数は、ヘッダーレコードの attributes フィールドでセットされるさまざまなビットを定義します。
enum {
kBTBadCloseMask = 0x00000001,
kBTBigKeysMask = 0x00000002,
kBTVariableIndexKeysMask = 0x00000004
};
|
それぞれのビットは次のような意味を持ちます。
kBTBadCloseMask- このビットは B ツリーが適切にクローズされているかどうかを示し、必要な場合は一貫性のチェックを行います。 このビットは HFS Plus B ツリーでは使用されません。 インプリメンテーションでは、このビットを予約済みとして扱う必要があります。
kBTBigKeysMask- このビットがセットされていると、インデックスおよびリーフノードに含まれるキーの
keyLength フィールドは UInt16 型になります。そうでない場合は UInt8 型になります。 このビットはすべての HFS Plus B ツリーでセットする必要があります。
kBTVariableIndexKeysMask- このビットがセットされていると、インデックスノードのキーはその
keyLength フィールドで指定されたバイト数を占有します。そうでない場合、インデックスノードのキーは常に maxKeyLength のバイト数を占有します。 HFS Plus カタログ B ツリーではこのビットをセットし、HFS Plus エクステント B ツリーではこのビットをクリアする必要があります。
ここで説明しなかったビットはすべて予約済みとして扱う必要があります。
ユーザデータレコード
ヘッダーノードの 2 番目のレコードは必ず 128 バイトの長さがあります。この小さな領域に B ツリーにかかわる情報を格納することができます。
HFS Plus のカタログ、エクステント、およびアトリビュートの各 B ツリーでは、このレコードは使用されず予約済みとなります。 HFS Plus のホットファイル B ツリーでは、このレコードにホットファイルレコードプロセスの一般情報が格納されます。
マップレコード
ヘッダーノードの残された領域は 3 番目のレコードであるマップレコードによって占有されます。 マップレコードは、B ツリー内のどのノードが使用されていて、どのノードが使用されていないかを示すビットマップです。 これらのビットはアロケーションファイルのビットと同じ方法で解釈されます。
ノード記述子、ヘッダーレコード、予約されているレコード、およびレコードオフセットをまとめると、ヘッダーノードの中の 256 バイトが占有されます。 このため、マップレコードのサイズ(バイト単位)は nodeSize から 256 を差し引いた値になります。 B ツリー内に、ヘッダーノードのマップレコードで表すことのできるノードを超えるノードが存在する場合は、マップノードが追加のアロケーションデータを格納するために使用されます。
マップノード
ヘッダーノードのマップレコードに十分なサイズがなくて、B ツリー内のすべてのノードを表すことができない場合、残ったアロケーションデータを格納するためにマップノードが使用されます。 この場合、ヘッダーノードのノード記述子に含まれる fLink フィールドには先頭のマップノードのノード数が含まれます。
マップノードはノード記述子と 1 つのマップレコードから構成されます。 このマップレコードはヘッダーノードに含まれるマップノードの続きです。 このマップレコードのサイズは、ノード全体のサイズからノード記述子のサイズ(14 バイト)、2 つのオフセット(4 バイト)、および 2 バイトの空き領域を差し引いた値になります。 つまり、マップレコードのサイズはノード全体のサイズから 20 バイトを引いた値になり、常に 4 バイトの偶数倍になります。 なお、マップレコードの先頭は 4 バイト境界に揃えられていません。 マップレコードはノード記述子の直後(14 バイトのオフセット)から始まります。
B ツリーは必要な数のマップノードを使用し、B ツリー内にあるすべてのノードのアロケーションデータを提供します。 複数のマップノードはヘッダーノードから始まり、それらのノード記述子に含まれる fLink フィールドを介して連結されています。 最後のマップノードのノード記述子に含まれる fLink フィールドの値はゼロです。 bLink フィールドはマップノードでは使用されず、すべてのマップノードでゼロにセットされていなければなりません。
|
注意:
bLink フィールドを使用しなくても HFS ボリュームフォーマットの一貫性は維持されますが、現実には設計全体の一貫性は維持されません。
|
キーを含むレコード
インデックスおよびリーフノードのレコードは共通の構造を持っています。 これらのレコードには、keyLength、キーそのもの、レコードデータがこの順番に格納されています。
レコードの先頭部分である keyLength は、B ツリーのヘッダーレコードに含まれる attributes フィールドの値に応じて、UInt8 または UInt16 のいずれかになります。 attributes フィールドの kBTBigKeysMask ビットがセットされていると、keyLength は UInt16 になり、そうでなければ UInt8 になります。 このフィールドに格納されているキーの長さに keyLength フィールドそのもののサイズは含まれていません。
|
重要:
すべての HFS Plus B ツリーでは、それらのキーの長さに UInt16 を使用します。
|
keyLength の直後にキーそのものが続きます。 キーの長さはノードのタイプと B ツリーの属性によって決まります。 リーフノードでは、キーの長さは常に keyLength によって決まります。 インデックスノードの場合、キーの長さは、ヘッダーレコードに含まれる B ツリー属性の kBTVariableIndexKeysMask ビットの値によって変わります。 このビットがクリアされていると、キーは B ツリーヘッダーレコードの maxKeyLength フィールドで指定されている一定のバイト数を占有します。 一方、このビットがセットされていると、キーの長さはキーレコードの keyLength フィールドによって決定されます。
キーの後にはレコードのデータが続きます。 このデータのフォーマットは、次の 2 つのセクションで説明するように、ノードのタイプによって異なります。 ただし、データは常に 2 バイト境界に揃えられ、偶数バイトを占有します。 第 1 のアライメント条件を満たすため、keyLength のサイズとキーのサイズの合計が奇数になる場合は、キーとデータの間にパッドバイトを挿入する必要があります。 また、第 2 のアライメント条件を満たすため、データサイズが奇数の場合はデータの後にパッドバイトを追加する必要があります。
インデックスノード
インデックスノードに含まれるレコードはポインタレコードと呼ばれます。 これらのレコードには、UInt32 で表される keyLength、キー、およびノード番号が含まれます。 ポインタレコードで指定された番号を持つノードは、インデックスノードの子ノードと呼ばれます。 1 つのインデックスノードは、ノードのサイズとノードに含まれるキーのサイズによって、2 つまたはそれ以上の子ノードを持ちます。
|
注意:
必ずしもルートノードが存在する必要はありません(ツリーが空の場合)。 また、ルートノードが存在する場合でも、必ずしもインデックスノードは必要ありません(つまり、すべてのレコードが 1 つのノードに収まりきるのなら、1 つのリーフノードだけで十分です)。
|
リーフノード
B ツリーの最も下位のレベルはリーフノードによって独占されます。 このノードには、ポインタレコードの代わりにデータレコードが含まれます。 データレコードには、keyLength、キー、およびキーに関連付けられたデータが含まれます。 このデータが可変長である場合もあります。
HFS Plus B ツリーでデータレコードに含まれるデータは、キーに関連づけられた HFS Plus ボリューム構造(CatalogRecord、ExtentRecord、AttributeRecord など)です。
キーを含むレコードの検索
B ツリーは、効率的な検索、挿入、および削除を可能にするため高度に構造化されています。 この構造は主としてキーを含むレコード (ポインタレコードとデータレコード) と、それらを格納しているノード (インデックスノードおよびリーフノード) に影響します。 次に、インデックスノードとリーフノードで使用される順序の要件を示します。
- キーを含むレコードはそれらのキーが昇順になるようにノード内に配置する必要があります。
- あるレベルにあるすべてのノード(同じ
height フィールドの値を持つノード)は、それらの fLink および bLink フィールドを介して連結されている必要があります。 最小のキーを持つノードはチェーンの先頭に位置し、その bLink フィールドはゼロでなければなりません。 また、最大のキーを持つノードはチェーンの末尾に位置し、その fLink フィールドはゼロでなければなりません。
- どのノードの場合も、そのノードに含まれるすべてのキーは、チェーン内の次のノード(
fLink によってポイントされる)に含まれるすべてのキーよりも小さくなければなりません。 同様に、そのノードに含まれるすべてのキーはチェック内の前のノード(bLink によってポイントされる)に含まれるすべてのキーよりも大きくなければなりません。
このような方法で配列されたキーを保持することで、B ツリーをすばやく検索して、特定のキーに対応するデータを見つけることが可能になります。 図 4 に、架空のキーを含む B ツリーのサンプルを示します(この例のキーは単純な整数であるとします)。
インプリメンテーションにおいて特定の検索キーに対応するデータを検索する場合、検索はルートノードから開始されます。 先頭のレコードを起点に、検索キーと同じかそれ未満のキーのうちの最大のキーを持つレコードを検索します。 この後、検索対象は子ノード(通常はインデックスノード)に移り、同じプロセスが繰り返されます。
このプロセスはリーフノードの達するまで続けられます。 リーフノードで検出したキーが検索キーに等しい場合、検出されたレコードには検索キーに対応する目的のデータが含まれます。 また、検出したキーが検索キーと等しくない場合、その検索キーは B ツリー内に存在しないということになります。
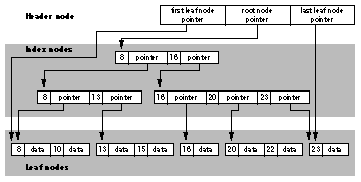 図 4. B ツリーのサンプル
HFS の B ツリーと HFS Plus の B ツリーの比較
HFS Plus 上の B ツリーの構造は、HFS ボリュームで使用される B ツリーの構造と密接な関係があります。 これらの構造の間には、ノードのサイズ、インデックスノード内のキーのサイズ、およびキー長のサイズ(UInt8 と UInt16)という 3 つの大きな違いがあります。
ノードのサイズ
HFS B ツリーでは、ノードは常に 512 バイトの固定長を持ちます。
HFS Plus B ツリーでは、ノードのサイズはヘッダーノードに含まれるフィールド(nodeSize)によって決まります。 ノードのサイズは 512 から 32,768 の範囲にある2のべき乗値でなければなりません。 インプリメンテーションでは、nodeSize フィールドを使って、実際のノードサイズを決定する必要があります。
|
注意:
ヘッダーノードは常に B ツリーの先頭にあり、B ツリーのノードサイズがわからなくても容易に見つけることができます。
|
HFS Plus では次のようなデフォルトのノードサイズが使用されます。
- カタログファイルの場合は 4KB(Mac OS X では 8KB)
- エクステントオーバーフローファイルの場合は 1KB(Mac OS X では 4KB)
- アトリビュートファイルの場合は 4KB
これらのサイズはボリュームを初期化するときに設定され、その後は容易には変更できません。 異なるノードサイズで HFS Plus ボリュームを初期化することは認められていますが、ノードサイズには、インデックスノードが 2 つの最大サイズのキー(およびノード記述子、レコードオフセット、子へのポインタなどのその他のオーバーヘッドを含めて)を含むことができるように十分なサイズを割り当てる必要があります。
|
重要:
カタログファイルのノードサイズは少なくとも kHFSPlusCatalogMinNodeSize(4096)でなければなりません。
|
|
重要:
アトリビュートファイルのノードサイズは少なくとも kHFSPlusAttrMinNodeSize(4096)でなければなりません。
|
インデックスノードのキーサイズ
HFS B ツリーの場合、インデックスノードに含まれるすべてのキーは固定長の領域、つまりその B ツリーの最大のキー長を占有します。 これにより、インデックスノード内部で新しいキーを格納するために十分な空き領域があるかどうかを心配しなくても、あるキーを別のキーで置き換えることができるため、レコードの挿入や削除のアルゴリズムが簡略化されます。 ただし、キーが可変長のときには(キー長がファイル名の長さによって変わるカタログファイルの中などで)、ある程度の領域の浪費が発生します。
HFS Plus B ツリーの場合、インデックスノードに含まれるキーはサイズを変えることができます。 これにより、レコードの挿入や削除のアルゴリズムは複雑になりますが、キーが可変長のときにも(カタログファイルなど)、領域の浪費を抑えることができます。 また、このことは、キーの実際のサイズによって、インデックスノードに含まれるキーの数が異なるということも意味します。
先頭に戻る
カタログファイル
HFS Plus では、カタログファイルを使って、ボリューム上にあるファイルとフォルダの階層に関する情報を保守します。 カタログファイルは B ツリーファイルとして編成されており、ヘッダーノード、インデックスノード、リーフノード、および(必要な場合は)マップノードから構成されます。 カタログファイルの先頭のエクステント(とファイルのヘッダーノード)はボリュームヘッダーの中に格納されています。 インプリメンテーションは、カタログファイルのヘッダーノードから B ツリーのルートノードのノード番号を取得することができます。 また、前のセクションで説明したように、ルートノードから B ツリーのキーを検索することができます。
「B ツリー」のセクションでは、HFS Plus B ツリーのノードサイズに関する標準的な規則を定義しました。 カタログファイルも B ツリーであるため、カタログファイルは当然のことながらこの規則の必要条件を継承します。 また、カタログファイルのノードサイズは少なくとも 4KB(kHFSPlusCatalogMinNodeSize)でなければなりません。
カタログファイルに含まれるそれぞれのファイルやフォルダには、重複のないカタログノード ID(CNID)が割り当てられています。 フォルダの場合、CNID はフォルダ ID であり、ディレクトリ ID または dirID と呼ばれることもあります。また、ファイルの場合は、それはファイル ID になります。 特定のファイルまたはフォルダについて、親 ID とは、そのファイルまたはフォルダを含むフォルダ、つまり親フォルダの CNID のことです。
カタログノード ID は CatalogNodeID データ型によって定義されます。
typedef UInt32 HFSCatalogNodeID;
|
先頭から 16 の CNID はアップルが使用するために予約されており、次のような標準的な割り当てを含んでいます。
enum {
kHFSRootParentID = 1,
kHFSRootFolderID = 2,
kHFSExtentsFileID = 3,
kHFSCatalogFileID = 4,
kHFSBadBlockFileID = 5,
kHFSAllocationFileID = 6,
kHFSStartupFileID = 7,
kHFSAttributesFileID = 8,
kHFSRepairCatalogFileID = 14,
kHFSBogusExtentFileID = 15,
kHFSFirstUserCatalogNodeID = 16
};
|
これらの定数は次のような意味を持ちます。
kHFSRootParentID- ルートフォルダの親 ID。
kHFSRootFolderID- ルートフォルダのフォルダ ID。
kHFSExtentsFileID- エクステントオーバーフローファイルのファイル ID。
kHFSCatalogFileID- カタログファイルのファイル ID。
kHFSBadBlockFileID- 不良ブロックファイルのファイル ID。 不良ブロックファイルは特殊ファイルではなく、むしろユーザファイルの 1 つです。 詳細については、「不良ブロックファイル」を参照してください。
kHFSAllocationFileID- アロケーションファイル(HFS Plus で導入された)のファイル ID。
kHFSStartupFileID- スタートアップファイル(HFS Plus で導入された)のファイル ID。
kHFSAttributesFileID- アトリビュートファイル(HFS Plus で導入された)のファイル ID。
kHFSRepairCatalogFileID- カタログファイルの再構築時に
fsck_hfs によって一時的に使用される。
kHFSBogusExtentFileIDExchangeFiles オペレーションの間に一時的に使用される。kHFSFirstUserCatalogNodeID- ユーザファイルおよびユーザフォルダが使用できる最初の CNID。
また、ゼロの CNID は使用されることがなく、nil 値として働きます。
通常、CNID は kHFSFirstUserCatalogNodeID から始まって、シーケンシャルに割り当てられます。 2000 年 1 月 18 日以前の仕様の HFS Plus では、ボリュームヘッダーの nextCatalogID フィールドが、ボリューム上の最大 CNID よりも大きい必要がありました(インプリメンテーションが nextCatalogID を使用して、新規作成されたファイルまたはディレクトリに割り当てる CNID を決められるように )。 しかし、高い頻度でファイルやディレクトリを作成するボリューム(処理量の多いサーバなど)では、CNID 値が足りなくなる可能性があるため、これは問題になることがあります。
現在は、HFS Plus ボリュームでは、CNID 値が循環し再利用できるようになっています。 ボリュームヘッダーの attributes フィールド内の kHFSCatalogNodeIDsReusedBit は、CNID 値が循環し再利用されたことを示すためにセットされます。 kHFSCatalogNodeIDsReusedBit がセットされていると、nextCatalogID フィールドは既存の CNID よりも大きい必要はなくなります。
kHFSCatalogNodeIDsReusedBit がセットされているときでも、nextCatalogID をヒントとして使用して、新規作成されたファイルまたはディレクトリに CNID を割り当てることは可能ですが、インプリメンテーションの中で、使用する CNID が現在使用されていないことを確認する必要があります(使用されている場合には別の値を選びます)。 nextCatalogID の CNID 番号がすでに使用されている場合、インプリメンテーションは使用されていない CNID が見つかるまで単純に nextCatalogID をインクリメントしていくことができます。 nextCatalogID がオーバーフローしてゼロになった場合、kHFSCatalogNodeIDsReusedBit をセットして、nextCatalogID を kHFSFirstUserCatalogNodeID にセットする必要があります(予約済みの CNID 値の使用を避けるため)。
|
注意:
Mac OS X バージョン 10.2 以降および Mac OS 9 のすべてのバージョンでは、kHFSCatalogNodeIDsReusedBit がサポートされています。
|
カタログファイルは B ツリーファイルであるため、その基本的な構造は B ツリーの定義を継承します。 これ以外に、HFS Plus カタログファイルについて次の 2 つのことだけがわかっていれば、そのデータを解釈することができます。
- インデックスおよびリーフノードの両方で使用されるキーのフォーマット。
- リーフノードデータレコード(ファイル、フォルダ、およびスレッドレコード)のフォーマット。
カタログファイルのキー
特定のファイル、フォルダ、またはスレッドレコードについて、カタログファイルのキーは親フォルダの CNID とファイルまたはフォルダの名前から構成されています。 この構造体は HFSPlusCatalogKey 型を使って記述されます。
struct HFSPlusCatalogKey {
UInt16 keyLength;
HFSCatalogNodeID parentID;
HFSUniStr255 nodeName;
};
typedef struct HFSPlusCatalogKey HFSPlusCatalogKey;
|
それぞれのフィールドは次のような意味を持ちます。
keyLengthkeyLength フィールドは、B ツリー内にあるキーを含むすべてのレコードによって必要とされます。 すべての HFS Plus B ツリーと同様に、カタログファイルは長いキー長(UInt16)を使用します。parentID- ファイルおよびフォルダレコードの場合、これはレコードによって表されるファイルまたはフォルダを含むフォルダです。 スレッドレコードの場合、これはファイルまたはフォルダそのものの CNID です。
nodeName- このフィールドには、完全に分解された Unicode 文字が標準的な順序で含まれます。 ファイルまたはフォルダレコードの場合、これは、
parentID フォルダ内にあるファイルまたはフォルダの名前です。 また、スレッドレコードの場合、これは空白文字列です。
|
重要:
キーの長さは nodeName フィールドに格納されている文字列の長さによって変わり、名前を格納するために必要なバイト数だけを占有します。 keyLength フィールドはキーの実際の長さを決定し、kHFSPlusCatalogKeyMinimumLength(6)から kHFSPlusCatalogKeyMaximumLength(516)の範囲で変動します。
|
|
注意:
カタログファイルは、Mac OS File Manager プログラミングインタフェースを使ってファイルまたはフォルダを指定する標準的な方法を反映していますが、検索対象となるボリュームのカタログを決定するボリューム参照番号だけは例外です。
|
カタログファイルのキーはまず parentID によって比較され、さらに nodeName によって比較されます。 parentID は符号なし 32 ビット整数として比較されます。 大文字小文字が区別される HFSX ボリュームの場合、nodeName 内の文字は 16 ビットの整数値の並びとして比較されます。 大文字小文字を区別しない HFSX ボリュームおよび HFS Plus ボリュームの場合、nodeName は、「文字列比較アルゴリズム」のセクションで説明するように、大小文字を区別せずに比較する必要があります。
カタログツリー内でカタログキーを使ってファイル、フォルダ、およびスレッドレコードを検索する方法の詳細については、「カタログツリーの使い方」を参照してください。
カタログファイルのデータ
カタログファイルのリーフノードは、4 種類の異なるデータレコードを含むことができます。
- 単一のフォルダに関する情報を含むフォルダレコード。
- 単一のファイルに関する情報を含むファイルレコード。
- フォルダとその親フォルダとのリンクを提供し、フォルダ ID を指定するだけでフォルダレコードの検索を可能にするフォルダスレッドレコード。
- ファイルとその親フォルダとのリンクを提供し、ファイル ID を指定するだけでファイルレコードの検索を可能にするファイルスレッドレコード (フォルダスレッドレコードとファイルスレッドレコードの両方で、スレッドレコードはファイルまたはフォルダ ID を実際の親ディレクトリIDと名前にマップするするために使用されます)。
それぞれのレコードは、カタログデータレコードのタイプを記述する recordType フィールドで始まります。 recordType フィールドには、次のいずれかの値が含まれます。
enum {
kHFSPlusFolderRecord = 0x0001,
kHFSPlusFileRecord = 0x0002,
kHFSPlusFolderThreadRecord = 0x0003,
kHFSPlusFileThreadRecord = 0x0004
};
|
それぞれの値は次のような意味を持ちます。
kHFSPlusFolderRecord- このレコードはフォルダレコードです。
HFSPlusCatalogFolder 型を使って、データを解釈することができます。
kHFSPlusFileRecord- このレコードはファイルレコードです。
HFSPlusCatalogFile 型を使って、データを解釈することができます。
kHFSPlusFolderThreadRecord- このレコードはフォルダススレッドレコードです。
HFSPlusCatalogFile 型を使って、データを解釈することができます。
kHFSPlusFileThreadRecord- このレコードはファイルスレッドレコードです。
HFSPlusCatalogFile 型を使って、データを解釈することができます。
次に続く 3 つのセクションでは、フォルダ、ファイル、およびスレッドレコードについて詳細に説明します。
|
注意:
recordType フィールドの位置と、各種レコードタイプについて選ばれている定数は、HFS および HFS Plus ボリュームの両方を処理する共通のコードを作成する場合に特に便利です。
HFS では、recordType フィールドは 1 バイトですが、必ずその後に、値が必ずゼロである 1 バイトの予約済みのフィールドが続きます。 HFS Plus では、recordType フィールドは 2 バイトです。 このため、次に示す適切な定数を使用して、HFS Plus の 2 バイトの recordType フィールドを使って、HFS レコードを検査することができます。
|
enum {
kHFSFolderRecord = 0x0100,
kHFSFileRecord = 0x0200,
kHFSFolderThreadRecord = 0x0300,
kHFSFileThreadRecord = 0x0400
};
|
それぞれの値は次のような意味を持ちます。
kHFSFolderRecord- このレコードは HFS フォルダレコードです。
HFSCatalogFolder 型を使って、データを解釈することができます。
kHFSFileRecord- このレコードは HFS ファイルレコードです。
HFSCatalogFile 型を使って、データを解釈することができます。
kHFSFolderThreadRecord- このレコードは HFS フォルダスレッドレコードです。
HFSCatalogThread 型を使って、データを解釈することができます。
kHFSFileThreadRecord- このレコードは HFS ファイルスレッドレコードです。
HFSCatalogThread 型を使って、データを解釈することができます。
カタログフォルダレコード
カタログフォルダレコードは、ボリューム上にある特定のフォルダに関する情報を保持するために B ツリーファイル内で使用されます。 このレコードのデータは HFSPlusCatalogFolder 型によって記述されます。
struct HFSPlusCatalogFolder {
SInt16 recordType;
UInt16 flags;
UInt32 valence;
HFSCatalogNodeID folderID;
UInt32 createDate;
UInt32 contentModDate;
UInt32 attributeModDate;
UInt32 accessDate;
UInt32 backupDate;
HFSPlusBSDInfo permissions;
FolderInfo userInfo;
ExtendedFolderInfo finderInfo;
UInt32 textEncoding;
UInt32 reserved;
};
typedef struct HFSPlusCatalogFolder HFSPlusCatalogFolder;
|
それぞれのフィールドは次のような意味を持ちます。
recordType- カタログデータレコードのタイプ。 フォルダレコードの場合、この値は常に
kHFSPlusFolderRecord です。
flags- このフィールドにはフォルダに関するビットフラグが含まれます。 現在のところ、フォルダレコードに対応するビットは定義されていません。 インプリメンテーションでは、これを予約済みのフィールドとして扱う必要があります。
valence- このフォルダに直接的に含まれているファイルとフォルダの数。 この値は、キーの
parentID がこのフォルダの folderID に等しいファイルおよびフォルダレコードの数と等しくなります。
|
重要:
従来の Mac OS File Managerプログラミングインタフェースでは、各フォルダが 32,767 以下の valence を持つ必要があります。 ボリュームを Mac OS でも使用できるようにする場合、インプリメンテーションではこの制限に従う必要があります。 32,768 以上の値は問題となります。32,767 以下であれば問題はありません。 これは、以前の Mac OS API に適用されていたインプリメンテーション上の制限です。PBGetCatInfo が 32,768 以上の項目にはアクセスできなかったのです。 実際問題として、単一のフォルダ内にこれに近い数の項目が存在すると、多くのプログラムが正常に動作しなくなる可能性があります。 このため、ボリュームフォーマットがフォルダ内の 32,767 を超える項目を許可する場合でも、現時点ではこの制限を超えることは良い考えとはいえません。
|
folderID- このフォルダの CNID。 なお、フォルダレコードのキーにはフォルダそのもの CNID ではなく、フォルダの親の CNID が含まれます。
createDate- フォルダが作成された日付と時刻。 フォーマットの詳細については、「HFS Plus の日付」を参照してください。 繰り返しになりますが、ボリュームヘッダーの
createDate は GMT フォーマットでは格納されず、日付と時刻のフォーマットは地方時になります (さらに、ボリュームが HFS ラッパーを持つ場合は、MDB 内の作成日がボリュームヘッダー内の createDate と同じ値になる必要があります)。
contentModDate- フォルダの内容が最後に変更された日付と時刻。 これは、このフォルダ内のファイルまたはフォルダが作成または削除された日時、またはこのフォルダ内のファイルまたはフォルダが移動された日時に対応します。 フォーマットの詳細については、「HFS Plus の日付」を参照してください。
|
注意:
従来の Mac OS API では、修正日の取得または設定を行うときに contentModDate を使用します。 従来の Mac OS API は attributeModDate フィールドを予約済みフィールドとして扱います。
|
attributeModDate- フォルダのカタログレコードの任意のフィールドが最後に変更された日付と時刻。 インプリメンテーションでは、このビットを予約済みとして扱うことができます。 Mac OS X では、BSD API がこのフィールドをフォルダの変更時間として使用します(
struct stat の st_ctime フィールドに返されます)。 Mac OS 8 および 9 では、このフィールドは予約済みとして扱われます。 フォーマットの詳細については、「HFS Plus の日付」を参照してください。
accessDate- フォルダの内容が最後に読み込まれた日付と時刻。 HFS カタログレコードの中に、このフィールドに類似するものはありません。 フォルダの内容が最後に読み込まれた日時を示します。 このフィールドは、ボリュームが Mac OS X および非 Mac OS プラットフォーム上にマウントされるときに POSIX のセマンティックスをサポートするために用意されています。 フォーマットの詳細については、「HFS Plus の日付」を参照してください。
|
重要:
HFS Plus の従来の Mac OS のインプリメンテーションでは accessDate フィールドが維持されません。 従来の Mac OS で新しく作成されたフォルダの accessDate の値はゼロになります。
|
backupDate- フォルダが最後にバックアップされた日付と時刻。 ボリュームフォーマットにおいては、このフィールドに対して特に何もする必要はありません。このフィールドは、ユーザプログラムの便宜を図る目的でのみ定義されています。 フォーマットの詳細については、「HFS Plus の日付」を参照してください。
permissions- このフィールドにはフォルダへのアクセス権が含まれます。これは、POSIX や AFP で定義されているものに類似しています。 フォーマットの詳細については、「HFS Plus のアクセス権」を参照してください。
|
重要:
HFS Plus の従来の Mac OS のインプリメンテーションは permissions フィールドを使用しません。 従来の Mac OS で作成されたフォルダでは、フィールド全体が 0 に設定されます。
|
userInfo- このフィールドには、Mac OS の Finder によって使用されている情報が含まれます。 この構造体の内容は厳密には HFS Plus 仕様には含まれませんが、一般的な情報を Finder 情報のセクションに示しました。
finderInfo- このフィールドには、Mac OS の Finder によって使用されている情報が含まれます。 この構造体の内容は厳密には HFS Plus 仕様には含まれませんが、一般的な情報を Finder 情報のセクションに示しました。
textEncoding- フォルダ名の元のテキストエンコーディングに関するヒント。 このヒントは、名前を Mac OS エンコーディッド Pascal 文字列に変換するときの精度を向上させるために使用できます。 詳細については、「テキストエンコーディング」を参照してください。
reserved- インプリメンテーションでは、これを予約済みのフィールドとして扱う必要があります。
カタログファイルレコード
カタログファイルレコードは、ボリューム上にある特定のファイルに関する情報を保持するためにカタログ B ツリーの中で使用されます。 レコードのデータは HFSPlusCatalogFile 型によって記述されます。
struct HFSPlusCatalogFile {
SInt16 recordType;
UInt16 flags;
UInt32 reserved1;
HFSCatalogNodeID fileID;
UInt32 createDate;
UInt32 contentModDate;
UInt32 attributeModDate;
UInt32 accessDate;
UInt32 backupDate;
HFSPlusBSDInfo permissions;
FileInfo userInfo;
ExtendedFileInfo finderInfo;
UInt32 textEncoding;
UInt32 reserved2;
HFSPlusForkData dataFork;
HFSPlusForkData resourceFork;
};
typedef struct HFSPlusCatalogFile HFSPlusCatalogFile;
|
それぞれのフィールドは次のような意味を持ちます。
recordType- カタログデータレコードのタイプ。 ファイルレコードの場合、この値は常に
kHFSPlusFileRecord です。
flags- このフィールドにはファイルに関するビットフラグが含まれます。 現在定義されているビットは以下に示します。 インプリメンテーションでは、未定義ビットを予約済みとして扱う必要があります。
reserved1- インプリメンテーションでは、これを予約済みのフィールドとして扱う必要があります。
fileID- このファイルの CNID。
createDate- ファイルが作成された日付と時刻。 フォーマットの詳細については、「HFS Plus の日付」を参照してください。
contentModDate- いずれかのフォークの拡張、切り詰め、または書き込みによって、ファイルの内容が最後に変更された日付と時刻。 フォーマットの詳細については、「HFS Plus の日付」を参照してください。
attributeModDate- ファイルのカタログレコードの任意のフィールドが最後に変更された日付と時刻。 インプリメンテーションでは、このビットを予約済みとして扱うことができます。 Mac OS X では、BSD API がこのフィールドをファイルの変更時間として使用します(
struct stat の st_ctime フィールドに返されます)。 Mac OS 8 および 9 では、このフィールドは予約済みとして扱われます。 フォーマットの詳細については、「HFS Plus の日付」を参照してください。
accessDate- ファイルの内容が最後に読み込まれた日付と時刻。 HFS カタログレコードの中に、このフィールドに類似するものはありません。 ファイルのいずれかのフォークの内容が最後に読み込まれた日時を示します。 このフィールドは、ボリュームが Mac OS X および非 Mac OS プラットフォーム上にマウントされるときに POSIX のセマンティックスをサポートするために用意されています。 フォーマットの詳細については、「HFS Plus の日付」を参照してください。
|
重要:
HFS Plus の従来の Mac OS のインプリメンテーションでは accessDate フィールドが維持されません。 従来の Mac OS で新しく作成されたファイルの accessDate の値はゼロになります。
|
backupDate- ファイルが最後にバックアップされた日付と時刻。 ボリュームフォーマットにおいては、このフィールドに対して特に何もする必要はありません。このフィールドは、ユーザプログラムの便宜を図る目的でのみ定義されています。 フォーマットの詳細については、「HFS Plus の日付」を参照してください。
permissions- このフィールドにはファイルへのアクセス権が含まれます。これは、POSIX で定義されているものに類似しています。 フォーマットの詳細については、「HFS Plus のアクセス権」を参照してください。
|
重要:
HFS Plus の従来の Mac OS のインプリメンテーションは permissions フィールドを使用しません。 従来の Mac OS で作成されたファイルでは、フィールド全体が 0 に設定されます。
|
userInfo- このフィールドには、Mac OS の Finder によって使用されている情報が含まれます。 詳細については「Finder 情報」のセクションを参照してください。
finderInfo- このフィールドには、Mac OS の Finder によって使用されている情報が含まれます。 この構造体の内容は厳密には HFS Plus 仕様には含まれませんが、一般的な情報を Finder 情報のセクションに示しました。
textEncoding- ファイル名の元のテキストエンコーディングのヒント。 このヒントは、名前を Mac OS エンコーディッド Pascal 文字列に変換するときの精度を向上させるために使用できます。 詳細については、「テキストエンコーディング」を参照してください。
reserved2- インプリメンテーションでは、これを予約済みのフィールドとして扱う必要があります。
dataFork- データフォークの位置とサイズに関する情報。
HFSPlusForkData 型の詳細については、「フォークデータ構造体」を参照してください。
resourceFork- リソースフォークの位置とサイズに関する情報。
HFSPlusForkData 型の詳細については、「フォークデータ構造体」を参照してください。
それぞれのフォークで、先頭から 8 つのエクステントはカタログファイルレコードの HFSPlusForkData フィールドによって記述されます。 フォークが十分に断片化していて、8 つを超えるエクステントが必要な場合、残りのエクステントはエクステントオーバーフローファイルのエクステントレコードによって記述されます。
次の定数は、ファイルレコードの flags フィールドに含まれるビットフラグを定義します。
enum {
kHFSFileLockedBit = 0x0000,
kHFSFileLockedMask = 0x0001,
kHFSThreadExistsBit = 0x0001,
kHFSThreadExistsMask = 0x0002
};
|
それぞれの値は次のような意味を持ちます。
kHFSFileLockedBit、kHFSFileLockedMaskkHFSFileLockedBit がセットされていると、いずれのフォークも拡張、切り詰め、書き込みを行うことができません。 読み込み専用(書き込み禁止)でオープンできるだけです。 ただし、カタログ情報(finderInfo や userInfo)は変更できる場合があります。kHFSThreadExistsBit、kHFSThreadExistsMask- このビットは、ファイルがスレッドレコードを持つことを示します。 HFS Plus のすべてのファイルはスレッドレコードを持つため、このビットは常にセットしておく必要があります。
カタログスレッドレコード
カタログスレッドレコードは、CNID とその CNID を使用するファイルまたはフォルダレコードをリンクするためにカタログ B ツリーの中で使用されます。 このレコードのデータは HFSPlusCatalogThread 型によって記述されます。
|
重要:
HFS のフォルダはスレッドレコードを必要としましたが、ファイルについてはオプションでした。 HFS Plus では、ファイルとフォルダの両方でスレッドレコードが必要です。
|
struct HFSPlusCatalogThread {
SInt16 recordType;
SInt16 reserved;
HFSCatalogNodeID parentID;
HFSUniStr255 nodeName;
};
typedef struct HFSPlusCatalogThread HFSPlusCatalogThread;
|
それぞれのフィールドは次のような意味を持ちます。
recordType- カタログデータレコードのタイプ。 スレッドレコードの場合、ファイルとフォルダのどちらを参照しているかにより、この値は
kHFSPlusFileRecord または kHFSPlusFolderRecord になります。 両方のタイプのスレッドレコードには同じデータが含まれます。
reserved1- インプリメンテーションでは、これを予約済みのフィールドとして扱う必要があります。
parentID- このスレッドレコードによって参照されるファイルまたはフォルダの親の CNID。
nodeName- このスレッドレコードによって参照されるファイルまたはフォルダの名前。
次のセクションでは、CNID だけを使ってファイルやフォルダを検索するためにスレッドレコードをどのように使用するかを説明します。
カタログツリーの使い方
ファイルおよびフォルダレコードは常に、空でない nodeName を含むキーを持ちます。 子に対するファイルおよびフォルダレコードはすべてカタログ内で連続しています。というのも、それらはすべてキー内に同一の parentID を持ち、nodeName のみが異なるためです。
スレッドレコードのキーは、ファイルまたはフォルダの CNID(親フォルダの CNID ではなく)と空(長さがゼロの)nodeName です。 これにより、CNID のみを使ったファイルやフォルダの検索が可能になります。 スレッドレコードには、ファイルまたはフォルダそのものの parentID および nodeName フィールドが含まれます。
CNID によるファイルまたはフォルダの検索は 2 段階のステップで処理されます。 第 1 のステップでは、CNID を使って、ファイルまたはフォルダに対するスレッドレコードを検出します。 このとき、ファイルまたはフォルダの親フォルダ ID と名前が評価されます。 第 2 のステップでは、その情報を使って、実際のファイルまたはフォルダレコードを検出します。
ファイルの中に他のファイルやフォルダは含まれないため、そのキーがファイルの CNID に等しい parentID と長さがゼロでない nodeName を持つカタログレコードは存在しません。 これらの未使用のキー値は予約されています。
Finder 情報
これらのデータ型の詳細および Finder がこれらを使用する方法については、「Finder Interface Reference」を参照してください。
struct Point {
SInt16 v;
SInt16 h;
};
typedef struct Point Point;
struct Rect {
SInt16 top;
SInt16 left;
SInt16 bottom;
SInt16 right;
};
typedef struct Rect Rect;
/* OSType は、4 つの 1 バイト文字を 1 つのまとめることで作成される
32 ビット値です。 */
typedef UInt32 FourCharCode;
typedef FourCharCode OSType;
/* Finder フラグ(finderFlags、fdFlags および frFlags) */
enum {
kIsOnDesk = 0x0001, /* ファイルとフォルダ(System 6) */
kColor = 0x000E, /* ファイルとフォルダ */
kIsShared = 0x0040, /* ファイルのみ(アプリケーションのみ)。クリア */
/* されている場合、アプリケーションは */
/* そのリソースフォークに書き込む必要が */
/* があるため、サーバ上で共有することが */
/* できない。 */
kHasNoINITs = 0x0080, /* ファイルのみ(機能拡張/コントロール */
/* パネルのみ) */
/* このファイルには INIT リソースは含まれない */
kHasBeenInited = 0x0100, /* ファイルのみ。 ファイルに、まだ追加されていない */
/* デスクトップデータベースリソース('BNDL'、'FREF'、 */
/* 'open'、'kind'...)が含まれている場合にのみ */
/* クリアする。 Finder */
/* によってのみセットされる。 */
/* フォルダ用に予約済み */
kHasCustomIcon = 0x0400, /* ファイルとフォルダ */
kIsStationery = 0x0800, /* ファイルのみ */
kNameLocked = 0x1000, /* ファイルとフォルダ */
kHasBundle = 0x2000, /* ファイルのみ */
kIsInvisible = 0x4000, /* ファイルとフォルダ */
kIsAlias = 0x8000 /* ファイルのみ */
};
/* 拡張フラグ(extendedFinderFlags、fdXFlags and frXFlags) */
enum {
kExtendedFlagsAreInvalid = 0x8000, /* 他の拡張フラグを */
/* 無視する */
kExtendedFlagHasCustomBadge = 0x0100, /* ファイルまたはフォルダに */
/* バッジリソースがある */
kExtendedFlagHasRoutingInfo = 0x0004 /* ファイルにルーティング情報 */
/* リソースが含まれている */
};
struct FileInfo {
OSType fileType; /* ファイルのタイプ */
OSType fileCreator; /* ファイルのクリエータ */
UInt16 finderFlags;
Point location; /* フォルダ内のファイルの場所 */
UInt16 reservedField;
};
typedef struct FileInfo FileInfo;
struct ExtendedFileInfo {
SInt16 reserved1[4];
UInt16 extendedFinderFlags;
SInt16 reserved2;
SInt32 putAwayFolderID;
};
typedef struct ExtendedFileInfo ExtendedFileInfo;
struct FolderInfo {
Rect windowBounds; /* フォルダウィンドウの位置と */
/* サイズ */
UInt16 finderFlags;
Point location; /* 親フォルダ内におけるフォルダの */
/* 位置。 (0, 0) に設定されている場合、Finder が */
/* 項目を自動的に配置 */
UInt16 reservedField;
};
typedef struct FolderInfo FolderInfo;
struct ExtendedFolderInfo {
Point scrollPosition; /* スクロール位置(アイコンビュー用) */
SInt32 reserved1;
UInt16 extendedFinderFlags;
SInt16 reserved2;
SInt32 putAwayFolderID;
};
typedef struct ExtendedFolderInfo ExtendedFolderInfo;
|
先頭に戻る
エクステントオーバーフローファイル
HFS Plus では、あるファイルに属するエクステント(連続するアロケーションブロック)のリストを保守することによって、そのファイルのフォークに属するアロケーションブロックを適切な順序で追跡します。 それぞれのエクステントはペアの数値(エクステントの先頭のアロケーションブロック番号とエクステント内のアロケーションブロックの数)によって表されます。 カタログ B ツリー内のファイルレコードには、各フォークの先頭から 8 つのエクステントのレコードが含まれます。 フォーク内に 8 つを超えるエクステントが存在する場合、それらのエクステントはエクステントオーバーフローファイルに格納されます。
カタログファイルと同様、エクステントオーバーフローファイルも B ツリーです。 ただし、エクステントオーバーフローファイルの構造は、カタログファイルの構造に比べるとかなり単純です。 エクステントオーバーフローファイルは、1 つの固定長キーと 1 つのデータレコードのタイプを持ちます。
エクステントオーバーフローファイルのキー
エクステントオーバーフローファイルのキーの構造体は HFSPlusExtentKey 型によって記述されます。
struct HFSPlusExtentKey {
UInt16 keyLength;
UInt8 forkType;
UInt8 pad;
HFSCatalogNodeID fileID;
UInt32 startBlock;
};
typedef struct HFSPlusExtentKey HFSPlusExtentKey;
|
それぞれのフィールドは次のような意味を持ちます。
keyLengthkeyLength フィールドは、B ツリー内にあるキーを含むすべてのレコードによって必要とされます。 すべての HFS Plus B ツリーと同様、エクステントオーバーフローファイルは長いキー長(UInt16)を使用します。 エクステントオーバーフローファイルのキーは常に同じ長さ、つまり kHFSPlusExtentKeyMaximumLength(10)を持ちます。forkType- このエクステントレコードが適用されるフォークのタイプ。 データフォークの場合は 0、リソースフォークの場合は 0xFF でなければなりません。
pad- インプリメンテーションでは、これをパディングフィールドとして扱う必要があります。
fileID- このエクステントレコードが適用されるファイルの CNID。
startBlock- このエクステントレコードによって記述される先頭のエクステントのフォークへの、アロケーションブロック内でのオフセット。 startBlock フィールドを使用すると、フォークへのオフセットを指定して、特定のエクステントを直接的に検索できるようになります。
|
注意:
通常、インプリメンテーションでは、カタログレコードの初期エクステントのコピーを保持します。 フォークの一部にアクセスを試みるときは、その位置がカタログレコードで記述されているエクステントを超えていないかどうか確認します。超えている場合は、そのオフセット(アロケーションブロック内での)を使って、適切なエクステント B ツリーレコードを検索します。 詳細については、「エクステントオーバーフローファイルの使い方」を参照してください。
|
2 つの HFSPlusExtentKey 構造体の内容は、fileID、forkType、startBlock という順序でフィールドを比較することによって比較されます。 したがって、特定のフォークに対するすべてのエクステントレコードは B ツリー内でグループ化され、ファイルの他のフォークに対するすべてのエクステントレコードはその隣に配置されます。
エクステントオーバーフローファイルのデータ
エクステントオーバーフローファイルのデータレコード(「エクステントレコード」)は HFSPlusExtentRecord 型によって記述されます。詳細については、「フォークデータ構造体」を参照してください。
|
重要:
HFSPlusExtentRecord には 8 つのエクステントに対する記述子が含まれていることを忘れないでください。 フォーク内の先頭から 8 つのエクステントはそのカタログファイルレコードの中に格納されます。 このため、あるフォークに対するエクステントレコードの数は ((エクステントの数 - 8 + 7) / 8) となります。
|
エクステントオーバーフローファイルの使い方
エクステントオーバーフローファイルについて記憶しておくべき最重要項目は、それが 8 つを超えるエクステントを含むフォークに対してのみ使用されるという点です。 たいていの場合、フォークは少数のエクステントを持ち、フォークに対するすべてのエクステント情報はそのカタログファイルレコードの中に保持されます。 しかし、より断片化されたフォークの場合、カタログファイルレコードに収まりきらないエクステント情報はエクステントオーバーフローファイルに格納されます。
インプリメンテーションがフォークオフセットをディスク上の特定の位置にマップする必要があるときは、まずカタログファイルレコード内のエクステントレコードが検索されます。 フォークオフセットがこれらのエクステントいずれかの内部にある場合、インプリメンテーションではエクステントオーバーフローファイルを参照することなく対応する位置を見つけることができます。
一方、フォークオフセットがカタログファイルレコードに記録されている最後のエクステントを超える場合は、エクステントオーバーフローファイルに格納されている次のエクステントレコードを検索する必要があります。 このレコードを検出するため、インプリメンテーションでは、フォーク(フォークのタイプとファイル ID)とフォークへのオフセット(開始ブロック)に関する情報を含んだキーを構成する必要があります。
エクステントレコードはレコードに含まれる先頭のエクステントのフォークオフセットを基準にしたキーを含むため、次のエクステントレコードのキーを構成するために必要なフォークオフセットを知るには、インプリメンテーションが先行するすべてのエクステントレコードを持っている必要があります。 たとえば、フォークがエクステントオーバーフローファイルに 2 つのエクステントレコードを持つ場合、2番目のエクステントレコードのキーに使用するフォークオフセットを計算するためには、先頭のエクステントレコードを読み込む必要があります。
しかし、エクステントキーに含まれる startBlock を使って、必要なレコードに直接移動することもできます。 次に、複雑な例を示します。
合計で 23 のエクステントを含むフォークを得たとします(非常に断片化されています)。 このエクステントの blockCounts は順に次のようになります。 6 つのアロケーションブロックを含む 1 つのエクステント、それぞれ 1 つのアロケーションブロックを含む 14 のエクステント、それぞれ 2 つのアロケーションブロックを含む 2 つのエクステント、7つのアロケーションブロックを含む 1 つのエクステント、およびそれぞれ 1 つのアロケーションブロックを含むさらに 5 つのエクステントです。 つまり、このフォークには合計で 36 のアロケーションブロックが含まれることになります。
カタログのフォークデータのブロック数は、6、1、1、1、1、1、1、1 となります。 エクステントオーバーフローレコードがあり、その startBlock は 13(0+6+1+1+1+1+1+1+1)で、ブロック数は 1、1、1、1、1、1、1、2 となります。 さらにもう 1 つエクステントオーバーフローレコードがあり、その startBlock は 22(13+1+1+1+1+1+1+1+2)で、ブロック数は 2、7、1、1、1、1、1、0 となります。 なお、後者のレコードには 7 つのエクステントが含まれるだけです。
ボリュームのアロケーションブロックサイズは 4K であるとし、108K のオフセットからファイルの読み込みを開始するとします。 データがボリューム上のどこにあるかということと、そこでデータがどの程度連続しているかということを知りたいとしましょう。
まず、108K(フォークオフセット)を 4K(アロケーションブロックサイズ)で割って、27 という値を得ます。 これはフォークの先頭からのアロケーションブロックの数に対応します。 ここで知る必要があるのは、フォークアロケーションブロック #27 がどこにあるかということです。 なお、27 は 13(カタログフォークデータに含まれるアロケーションブロックの数)を超えているため、エクステント B ツリーの中で検索を行う必要があります。
適切な fileID と forkType を使って検索キーを構築し、startBlock に 27(目的のフォークアロケーションブロック番号)を設定します。 この後、エクステント B ツリーで、そのキー値が検索キー以下になるレコードを検索します。 2 番目のエクステントオーバーフローレコード(startBlock = 22 を含むもの)が検出されます。 このレコードは同一の fileID と forkType を持つため有望です。 このとき、そのレコード内のどのエクステントを使用するかを正しく理解している必要があります。
27(目的のフォークアロケーションブロック)から 22(startBlock)を引き算して 5 という値を得ます。その結果、レコード内に 5 つのアロケーションブロックだけ「入った」位置にあるエクステントが対象になります。 まず先頭のエクステントを試します。 このエクステントの長さは 2 つのアロケーションブロックのみであるため、目的のエクステントはレコード内の先頭のエクステントの末尾からさらに 3 アロケーションブロック先にあります。 次のエクステントの長さは 7 つのアロケーションブロックです。 7 は 3 を超えているため、目的のフォークの位置はこのエクステント(第 2 のオーバーフローレコード内の 2 番目のエクステント)内にあることがわかります。 さらに、7 - 3 = 4 で、4 つのアロケーションブロックが連続している(つまり、16K)こともわかります。
この 2 番目のエクステント(つまり、blockCount が 7 であるエクステント)の startBlock の値が 444 であるとすると、それに 3 を加えます(目的の位置は検出したエクステントの中に 3 アロケーションブロックだけ入っているため)。 その結果、目的の位置はボリューム上のアロケーションブロック 444 + 3 = 447 の中であることになります。 つまり、HFS Plus ボリュームの先頭から 447 * 4K = 1788K の位置ということです (ボリュームヘッダーは常に HFS Plus ボリュームの先頭から 1K の位置で始まるため、目的のフォークの位置はボリュームヘッダーの先頭から 1787K ということになります)。
不良ブロックファイル
エクステントオーバーフローファイルは、不良ブロックファイルに関する情報を保持するためにも使用されます。 不良ブロックファイルは、何らかの障害によりデータの格納に使用できないディスク上の領域をマークするために使用します。 通常、このマークはディスク上の不良セクタをマップアウトするために使用されます。
|
注意:
HFS Plus ボリューム上のすべての領域はアロケーションブロックという概念を使って割り当てられています。 通常、アロケーションブロックはセクタよりも大きな領域を含みます。 このため、不良セクタが検出された場合、アロケーションブロック全体が使用できなくなります。
|
HFS Plus ボリュームが HFS ラッパに埋め込まれている場合(Mac OS が通常ハードディスクを初期化する方法)、HFS Plus ボリュームによって使用される領域は HFS ラッパー内で不良ブロックファイルに属するものとしてマークされます。 (あるボリュームの内部に別のボリュームがあるというのも奇妙に聞こえるかもしれませんが)。
不良ブロックファイルは、ユーザファイル(カタログ内にファイルレコードを持ちません)や特殊ファイル(ボリュームヘッダーによって参照されません)のいずれかと同じ意味のファイルではありません。 不良ブロックファイルは、エクステントオーバーフローファイルに含まれるエクステントレコードに対するキーとして特殊な CNID(kHFSBadBlockFileID)を使用します。 あるブロックが不良とマークされているとき、この CNID を含み、不良ブロックを取り囲むエクステントがエクステントオーバーフローファイルに追加されます。 また、そのブロックはアロケーションファイルの中では使用済みとマークされます。 このようなステップにより、ファイルシステムはデータを格納するためにこのブロックを使用できなくなります。
|
重要:
アロケーションファイルの中で不良ブロックを使用済みとマークするだけでは不十分であるため、不良ブロックファイルが必要になります。 HFS Plus ボリュームの一貫性をチェックする一般的な方法の 1 つとして、ボリューム上のすべてのアロケーションブロックが実際のデータによって使用されているかどうかを検証することがあります。 不良ブロックファイルのエクステントによってマークされていない不良ブロックを含むボリュームを対象にこのようなチェックを実行すると、不良ブロックが解放され、ファイルシステムのデータを格納するために再利用されてしまう場合があります。
|
不良ブロックエクステントレコードは常にデータフォークを参照すると見なされます。 キーの forkType フィールドは 0 でなければなりません。
|
注意:
エクステントレコードは最大で 8 つのエクステントを保持するため、不良ブロックエクステントを不良ブロックファイルに追加しても、必ずしも新しいエクステントレコードを追加する必要はありません。
|
HFS も類似したメカニズムを使って、不良ブロックに関する情報を格納します。 この機能は、HFS Plus ボリューム全体を HFS ディスク上の不良ブロックとして保持するために HFS ラッパーによって使用されます。
先頭に戻る
アロケーションファイル
HFS Plus はアロケーションファイルを使って、ボリューム内の各アロケーションブロックが現在何らかのファイルシステム構造に割り当てられているかどうかを監視し続けます。 アロケーションファイルの内容はビットマップです。 このビットマップには、ボリューム内の各アロケーションブロックごとに 1 つのビットが含まれます。 ビットがセットされている場合、対応するアロケーションブロックは現在何らかのファイルシステム構造によって使用されています。 また、ビットがクリアされている場合、対応するアロケーションブロックは現在使用されておらず、割り当てに使用することができます。
|
注意:
HFS はアロケーション情報を「ボリュームビットマップ」と呼ばれるボリューム上の特殊な領域に格納します。 HFS Plus によって使用されるアロケーションファイルのメカニズムにはいくつかの利点があります。
- ファイルを使用することで、ビットマップそのものをアロケーションブロックから割り当てることが可能になります。 これにより、ボリュームはただ 1 つのタイプのブロック、つまりアロケーションブロックから構成されることになり、ボリュームの構造が簡略化されます。 HFS では、512 バイトブロックを使ってアロケーションビットマップを保持し、アロケーションブロックを使ってファイルデータを保持するため、構造がより複雑になります。
- アロケーションファイルが連続している必要はなく、アロケーションデータとユーザデータが交互に現れてもかまいません。 最近の多くのファイルシステムでは、ファイルが大きくなるときのオーバーヘッドを低減するためにこの方法を使用しています。
- アロケーションファイルは拡張できるため、ディスク上のアロケーションブロックの数を増やすことが非常に容易になります。 これは、ディスク上のアロケーションブロックサイズを小さくしたり、ディスク全体のサイズを大きくする場合に役立ちます。
- アロケーションファイルは収縮させることも可能です。 これにより、サイズが変わるボリュームに合わせて最適なディスクイメージを作成することが容易になります。 ディスクイメージに含まれるアロケーションファイルは、最大のディスクのアロケーションデータを十分に保持できるようにサイズが決定されますが、データをより小さなディスクに書き込むときには収縮して元のサイズに戻ります。
|
アロケーションファイルの各バイトは 8 つのアロケーションブロックのステータスを保持します。 ファイル内のオフセット X のバイトには、アロケーションブロック (X * 8) から (X * 8 + 7) までのアロケーションステータスが含まれます。 各バイト内の最大有効ビットには番号が最も小さいアロケーションブロックに関する情報が保持され、最小有効ビットには番号が最も大きいアロケーションブロックに関する情報が保持されます。 リスト 1 に、アロケーションファイル全体をメモリに読み込んだという前提で、あるアロケーションブロックが使用中であるかどうかをテストする方法を示します。
static Boolean IsAllocationBlockUsed(UInt32 thisAllocationBlock,
UInt8 *allocationFileContents)
{
UInt8 thisByte;
thisByte = allocationFileContents[thisAllocationBlock / 8];
return (thisByte & (1 << (7 - (thisAllocationBlock % 8)))) != 0;
}
|
リスト 1 アロケーションブロックが使用中であるかどうかの判定
|
アロケーションファイルのサイズはボリューム内のアロケーションブロックの数によって決まり、さらにアロケーションブロックの数は、ディスクのサイズとボリュームのアロケーションブロックのサイズの両方によって決まります。 たとえば、1GB ディスク上に 1 つのボリュームがあり、アロケーションブロックサイズが 4KB の場合、アロケーションファイルのサイズは 256 キロビット(32KB または 8 つのアロケーションブロック)でなければなりません。 アロケーションファイルそのものもアロケーションブロックを使って割り当てられるため、アロケーションファイルは常に整数のアロケーションブロック数を占有します(そのサイズが切り上げられることもありますが)。
アロケーションファイルは対象となるボリュームサイズに必要な最小限のビット数よりも大きくなることがあります。 ビットマップ内の未使用ビットには必ずゼロを設定する必要があります。
|
注意:
アロケーションブロックの数は 32 ビット数によって決定されるため、アロケーションファイルのサイズは最大で 512MB まで拡張することができます。これは HFS の 8KB という制限に比べると、大幅な増大といえます。
|
|
重要:
ボリューム全体が複数のアロケーションブロックから構成されるため(ただし、前述のように代替ボリュームヘッダーは除外されることがあります)、ボリュームヘッダー、代替ボリュームヘッダー、および予約済み領域(先頭の 1024 バイトと最後の 512 バイト)も、アロケーションファイル内では割り当て済みとマークされていなければなりません。 これらの領域のために割り当てられたアロケーションブロックの実際の数は、アロケーションブロックサイズによって異なります。 これらの領域のいずれかを含むアロケーションブロックは、割り当て済みとしてマークする必要があります。
たとえば、512 バイトのアロケーションブロックが使用されている場合は、先頭の 3 つのアロケーションブロックと最後の 2 つのアロケーションブロックが割り当てられます。 また、1024 バイトのアロケーションブロックの場合は、先頭の 2 つのアロケーションブロックと最後のアロケーションブロックが割り当てられます。 アロケーションブロックサイズがこれよりも大きくなると、先頭と最後のアロケーションブロックだけがこれらの領域に割り当てられます。
これらの領域の詳細については、「ボリュームヘッダー」のセクションを参照してください。
|
先頭に戻る
アトリビュートファイル
HFS Plus のアトリビュートファイルは、将来、名前付きフォークをインプリメントするときのために予約されています。 アトリビュートファイルは B ツリーファイルとして組織されます。 これは、ボリュームヘッダーの HFSPlusForkData レコードによって記述される特殊ファイルですが、カタログファイルの中にエントリを持っていません。 アトリビュートファイルは 1 つの可変長キーと 3 つのデータレコードタイプを含み、カタログファイルとほぼ同程度の複雑さを持ちます。
ボリュームがアトリビュートファイルを持たないこともあります。 アトリビュートファイルの先頭のエクステント(ボリュームヘッダーに格納されている)がアロケーションブロックをまったく持たない場合、そのアトリビュートファイルは存在しません。
「B ツリー」のセクションでは、HFS Plus B ツリーのノードサイズに関する標準的な規則を定義しました。 アトリビュートファイルも B ツリーであるため、この規則の必要条件を継承します。 また、アトリビュートファイルのノードサイズは少なくとも 4KB(kHFSPlusAttrMinNodeSize)でなければなりません。
|
重要:
アトリビュート B ツリーの厳密な構成はまだ完全には設計されていません。 特に、次の点に注意してください。
- アトリビュート B ツリーに含まれるキーの構造は最終的に決定されておらず、今後も変更される場合があります。
- 属性のファイルデータレコードタイプが将来さらに定義される可能性もあります。
この仕様に準拠したインプリメンテーションでも、最終的な詳細仕様を使って属性に関する基本的な一貫性のチェックを実行できるかもしれません。 これらのチェックは最終的な属性仕様に準拠した将来のインプリメンテーションとも互換性を維持する予定です。 「アトリビュートおよびアロケーションファイルの一貫性のチェック」を参照してください。
|
アトリビュートファイルのデータ
|
重要:
アトリビュートファイルデータレコードのいくつかのタイプはすでに定義されています。 しかし、将来の仕様で追加のレコードタイプが定義される可能性もあります。 この仕様に準拠したインプリメンテーションでは、ここで定義されていないレコードタイプを無視する必要があります。
|
アトリビュートファイルのリーフノードには、「属性」と呼ばれるデータレコードが含まれます。 属性には 2 つのタイプがあります。
- 「フォークデータ属性」はデータが大きな属性に使用します。 属性のデータはボリューム上のエクステントに格納され、属性にはそれらのエクステントへの参照が含まれるだけです。
- 「拡張属性」はフォークデータ属性を拡大し、フォークデータ属性が 8 つを超えるエクステントを持てるようにします。
それぞれのレコードは、属性データレコードのタイプを記述する recordType フィールドで始まります。 recordType フィールドには次のいずれかの値が含まれます。
enum {
kHFSPlusAttrInlineData = 0x10,
kHFSPlusAttrForkData = 0x20,
kHFSPlusAttrExtents = 0x30
};
|
それぞれの値は次のような意味を持ちます。
kHFSPlusAttrInlineData- 将来の使用のために予約されています。
kHFSPlusAttrForkData- このレコードはフォークデータ属性です。
HFSPlusAttrForkData 型を使って、このデータを解釈することができます。
kHFSPlusAttrExtents- このレコードは拡張属性です。
HFSPlusAttrExtents 型を使って、このデータを解釈することができます。 kHFSPlusAttrExtents 型のレコードは、対応するレコードタイプ kHFSPlusAttrForkData のためのオーバーフローエクステントに過ぎません。 (kHFSPlusAttrForkData はカタログレコード、kHFSPlusAttrExtents はエクステントオーバーフローレコードのようなものと考えてください)。
次の 2 つのセクションでは、フォークデータ属性と拡張属性について詳細に説明します。
フォークデータ属性
フォークデータ属性は HFSPlusAttrForkData データ型によって定義されます。
struct HFSPlusAttrForkData {
UInt32 recordType;
UInt32 reserved;
HFSPlusForkData theFork;
};
typedef struct HFSPlusAttrForkData HFSPlusAttrForkData;
|
それぞれのフィールドは次のような意味を持ちます。
recordType- 属性データレコードのタイプ。 フォークデータ属性の場合、このフィールドは常に
kHFSPlusAttrForkData になります。
reserved- インプリメンテーションでは、これを予約済みのフィールドとして扱う必要があります。
theFork- 属性データの位置とサイズに関する情報。
HFSPlusForkData 型の詳細については、「フォークデータ構造体」を参照してください。
拡張属性
拡張属性は HFSPlusAttrExtents データ型によって定義されます。
struct HFSPlusAttrExtents {
UInt32 recordType;
UInt32 reserved;
HFSPlusExtentRecord extents;
};
typedef struct HFSPlusAttrExtents HFSPlusAttrExtents;
|
それぞれのフィールドは次のような意味を持ちます。
recordType- 属性データレコードのタイプ。 拡張属性の場合、このフィールドは常に
kHFSPlusAttrExtents になります。
reserved- インプリメンテーションでは、これを予約済みのフィールドとして扱う必要があります。
extents- このレコードによって記述される属性データの 8 つのエクステント。
HFSPlusExtentRecord 型の詳細については、「フォークデータ構造体」を参照してください。
アトリビュートおよびアロケーションファイルの一貫性のチェック
アトリビュートファイルのキー構造はまだ完全には指定されていませんが、インプリメンテーションでは、アロケーションファイルの一貫性をチェックするときにアトリビュートファイルの情報を使用することもできます。 アトリビュートファイルのリーフレコードはまだ完全には定義されていないため、インプリメンテーションではそれらを単純に何度も繰り返して、フォークデータ属性によって使用されているディスク上のアロケーションブロックを決定することができます。
詳細については、「アロケーションファイルの一貫性のチェック」を参照してください。
先頭に戻る
スタートアップファイル
スタートアップファイルは、HFS Plus を組み込み(ROM)サポートしないシステムをブートするときに必要となる情報を保持するための特殊ファイルです。 ブートローダは、HFS Plus ボリュームフォーマット(B ツリー、カタログファイルなど)の詳細に配慮することなく、スタートアップファイルを容易に検出することができます。 ボリュームヘッダーには、スタートアップファイルの先頭から 8 つのエクステントの位置が含まれます。
|
重要:
スタートアップファイルに 8 つを超えるエクステントが含まれることそれ自体は問題ではなく、ボリュームヘッダーに格納できなくなった残りのエクステントはエクステントオーバーフローファイルに置かれます。 ただし、このようにすることでスタートアップファイル本来の目的が損なわれてしまいます。
|
|
注意:
HFS Plus ディスクからブートを行うために、Mac OS はスタートアップファイルを使用しません。 後述するように、スタートアップファイルの代わりに HFS ラッパーを使用します。
|
先頭に戻る
ハードリンク
ハードリンクは、複数のディレクトリエントリが 1 つのファイルの内容を参照できるようにする機能です。 この方法を使用して 1 つのファイルに複数の名前を与えたり、場合によっては複数のディレクトリに含めることができます。 このセクションでは、Mac OS X においてハードリンクがどのように HFS Plus ボリュームにインプリメントされているかを説明します。
Mac OS X の HFS Plus ボリュームにおけるハードリンクのインプリメンテーションは、カタログレコードの既存のメタデータフィールドを使用して実現されました。 これにより、ハードリンクを理解したり解釈したりしなくても、個々のファイルをバックアップして回復するだけで、ハードリンクを使用するボリュームのバックアップと回復が可能になります。 HFS Plus のインプリメンテーションは、ハードリンクを自動的に追跡することもそうしないことも選べます。
HFS Plus におけるハードリンクは、いくつかのファイルの集合として表されます。 実際のファイルの内容(ハードリンクどうしで共有するもの)は特別な間接ノードファイルに格納されています。 この間接ノードファイルは、従来の UNIX ファイルシステムにおける inode に相当します。
HFS Plus は特別なハードリンクファイル(またはリンク)を使用して間接ノードファイルを参照(ポイント)します。 ファイル内容を参照するディレクトリエントリまたは名前ごとに 1 つのハードリンクがあります。
間接ノードファイルは、メタデータディレクトリと呼ばれる特別なディレクトリに格納されています。 このディレクトリは、ボリュームのルートディレクトリにあります。 メタデータディレクトリの名前は、4 つのヌル文字に「HFS+ Private Data」という文字列が続きます。 ディレクトリの作成日としては、ボリュームのルートディレクトリの作成日が設定されます。 ディレクトリの Finder 情報の kIsInvisible ビットおよび kNameLocked ビットがセットされています。 Finder 情報のアイコン位置 location は (22460, 22460) をポイントするように設定されます。 これらの Finder 情報の設定は必須ではありませんが、メタデータディレクトリの偶発的な変更を減らすことができます。 ハードリンクを自動的にたどるインプリメンテーションでは、通常のファイルシステムインタフェースからメタデータディレクトリにアクセスできないようにするべきです。
|
注意:
HFS Plus および大文字小文字を区別しない HFSX で使用される大文字小文字を区別しない Unicode 文字列比較では、ヌル文字がすべての文字の後に来るものと判定されので、メタデータディレクトリは一般にルートディレクトリの最後の項目となります。 大文字小文字が区別される HFSX ボリュームでは、ヌル文字は他の文字より先に来るので、メタデータディレクトリは一般にルートディレクトリの最初の項目となります。
|
間接ノードファイルには、リンク参照と呼ばれる特別な識別番号があります。 リンク参照は、1 つのボリューム上の間接ノードファイルの間では一意です。 リンク参照は、カタログノード ID とは無関係です。 新しい関節ノードファイルが作成されると、100 から 1073741923 までの間の値から無作為に選ばれた新しいリンク参照が割り当てられます。
間接ノードフィルのファイル名は、「iNode」という文字列の直後にゼロが先行しない数字に変換されたリンク参照が続くものとなります。 たとえば、リンク参照が 123 である間接ノードファイルの名前は「iNode123」となります。
間接ノードファイルは、ディレクトリではなく、必ずファイルである必要があります。 ディレクトリへのハードリンクは禁止されています。なぜなら、ハードリンクが祖先ディレクトリのいずれかをポイントするとディレクトリ階層に循環が生じてしまうためです。
アクセス許可における linkCount フィールドは、間接ノードファイルを参照するリンクの数の概算です。 ハードリンクを処理できるインプリメンテーションは、追加リンクを作成するときにこの値をインクリメントし、リンクを削除するときは値をデクリメントする必要があります。 ただし、インプリメンテーションによっては(従来の Mac OS など)は、ハードリンクを処理せず、linkCount の値が不正確となるような変更を加える可能性があります。 同様に、リンクが、存在しない間接ノードファイルを参照していることもありえます。 インプリメンテーションでは、リンクを削除する際に、linkCount のアンダーフローが生じないようにする必要があります。値がゼロなら、値を変更せずに起きます。
|
注意:
POSIX の stat または lstat ルーチンから stat 構造体の st_ino フィールドに返される inode 番号は、実際には間接ノードファイルのカタログノード ID であり、先述のリンク参照ではありません。
カタログノード ID の代わりに独立のリンク参照番号を使用する理由は、ハードリンクに特に対応していないユーティリティでもハードリンクをバックアップして回復できるようにするためです。 ユーティリティがファイル名、Finder 情報、およびアクセス権を保存する限り、ハードリンクも保存できます。
|
ハードリンクはカタログ内では通常のファイルです。 ハードリンクファイルのカタログノード ID は、リンクが参照する間接ノードファイルのカタログノード ID と異なり、他のハードリンクファイルのカタログノード ID とも異なります。
ハードリンクファイルのカタログレコード内における userInfo の fileType フィールドと fileCreator フィールドは、それぞれ kHardLinkFileType および kHFSPlusCreator に設定します。 ハードリンクファイルの作成日としては、メタデータトディレクトリの作成日を設定します。 ハードリンクファイルの作成日として、ボリュームのルートディレクトリの作成日を設定することもできます(メタデータディレクトリの作成日と異なる場合)。しかし、これは廃止になっています。 アクセス許可における iNodeNum フィールドには、リンクが参照する間接ノードファイルのリンク参照が設定されます。 従来の Mac OS の Finder との互換性を高めるためには、Finder フラグ群の kHasBeenInited フラグをセットしてください。 その他の Finder 情報およびカタログレコード内の他の日付は予約済みとなります。
enum {
kHardLinkFileType = 0x686C6E6B, /* 'hlnk' */
kHFSPlusCreator = 0x6866732B /* 'hfs+' */
}; |
POSIX のセマンティックスでは、オープンされているファイルのリンク解除(削除)が可能です。 オープンされているがリンク解除されたファイルは、HFS Plus ボリューム上にハードリンクのように格納されます。 オープンされているファイルが削除されると、名前が変更され、メタデータディレクトリに移されます。 新しい名前は「temp」という文字列に、カタログノード ID を 10 進数に変換した数字が続く名前となります。 最終的にファイルがクローズされると、一時ファイル名が削除できるようになります。 このような一時ファイルはすべて、マウントされていない HFS Plus ボリュームを修復する際に削除できます。
メタデータディレクトリの修復
ハードリンクまたはメタデータディレクトリのある HFS Plus ボリュームを修復する際には、修復する必要のあるいくつかの状態が考えられます。
- オープンされているが削除されているファイル(孤児となっているファイル)
- 孤児となった間接ノードファイル(参照するハードリンクがない)
- 破損ハードリンク(ハードリンクが存在するが、対応する間接ノードファイルが存在しない)
- 正しくないリンク数
- リンク参照が 0
オープンされているが削除されたファイルとは、名前が「temp」で始まり、メタデータディレクトリに格納されています。 ボリュームが使用中でない場合(マウントされておらず、他のユーティリティにも使用されていない)、これらのファイルは削除できます。 ジャーナルのあるボリュームは、アクティブなトランザクションのないボリュームでも、オープンされているが削除されていないファイルを削除する必要があるかもしれません。
孤児となった間接ノードファイル、破損ハードリンク、または不正リンク数を検出するには、カタログ内でハードリンクファイルをすべて探し出し、見つかったリンク参照ごとのハードリンクの数を、対応する間接ノードファイルのリンク数と比較します。
リンク参照の値が 0 であるハードリンクは無効です。 これは、カタログレコード内のアクセス許可を使用しないインプリメンテーションまたユーティリティを使用してハードリンクをコピーまたは回復した結果であるかもしれません。 正しいリンク参照を調べてハードリンクを修正できる可能性があります。 さもなければ、ハードリンクを削除するべきです。
先頭に戻る
シンボリックリンク
ハードリンクと同様に、シンボリックリンクも特別な種類のファイルであり、別のファイルまたはディレクトリを参照します。 シンボリックリンクは、参照先のファイルまたはディレクトリのパス名を格納します。
HFS Plus ボリュームでは、シンボリックリンクはカタログレコードの一部のフィールドに特別な値を持つ通常のファイルとして格納されます。 参照先のファイルのパス名は、データフォークに格納されます。 アクセス許可の fileMode フィールドのファイルタイプとしては、S_IFLNK が設定されます。 Carbon および Classic アプリケーションとの互換性確保のために、シンボリックリンクのファイルタイプは kSymLinkFileType に設定され、クリエータコードは kSymLinkCreator に設定されます。 シンボリックリンクのリソースフォークは長さがゼロで予約済みです。
enum {
kSymLinkFileType = 0x736C6E6B, /* 'slnk' */
kSymLinkCreator = 0x72686170 /* 'rhap' */
}; |
|
注意:
シンボリックリンクに格納されているパス名は、Mac OS X BSD および Cocoa のプログラミングインタフェースで使用される POSIX パス名とみなされます。 従来の Mac OS または Carbon のパス名ではありません。 パス名は UTF-8 でエンコードされます。 ヌル(ゼロ)のバイトのない有効な UTF-8 の並びでなければなりません。 パスは別のボリュームを参照することもできます。 パスは、既存のファイルまたはディレクトリを参照していなくても構いません。 パスは完全パスまたは部分的なパス(先頭のスラッシュがないパス)であることができます。 最大限の互換性確保のために、パスの長さは 1024 バイトまでにしておきます。
|
先頭に戻る
ジャーナル
HFS Plus ボリュームは、(停電やクラッシュが原因で)安全にアンマウントされなかったボリュームをマウントするときに回復をスピードアップするために、任意でジャーナルを持つことができます。 ジャーナルは、構造全体を走査する必要なく、ボリューム構造を一貫性のある状態にすばやく簡単に回復することを可能にします。 ジャーナルの対象はボリューム構造とメタデータに限られます。フォークの内容は保護しません。
背景
ボリュームに対する 1 つの変更が、ボリュームの複数の場所への連携された書き込みを必要とする場合があります。 変更の全部ではなく一部の書き込みがあった時点で障害が生じると、ボリュームは深刻なダメージを受け、データの壊滅的な喪失につながる可能性があります。
たとえば、ファイルまたはディレクトリを作成すると、カタログ B ツリーに 2 つのレコード(ファイルまたはフォルダレコード、および、そのスレッドレコード)を追加する必要があります。 リーフノードに新しいレコードのための余裕がなく、分割する必要があるかもしれません。 これは、一部のレコードが既存のノードから削除され、新しく割り当てられたノードに書き込まれるということです。 それには、分割対象のリーフノードの親にあたるインデックスノードを指す新しいキーとポインタを追加する必要があります(その際に、インデックスノードの分割が必要かもしれません)。 分割後でありながら、インデックスノードが更新される前に障害が発生すると、新しいノード内のすべての項目にアクセスできなくなります。 このような破損からの回復は時間を要し、不可能な場合もあります。
ジャーナルの目的は、相互に関連のある変更が加えられたときに、それらの変更が実際にすべて実行されるか、そのどれも実行されないかの、どちらかになることを保証することです。 これは、すべての変更を収集し、別の場所(ジャーナル)に保存しておくことによって実現されます。 変更のジャーナルがすべてディスクに書き込まれた後、そこで初めてそれらの変更がディスク上の本来の場所に実際に書き込まれます。 そのときに障害が発生した場合には、単純に変更をジャーナルから本来の場所にコピーすることができます。 ジャーナルへの書き込みが完全に終了しないうちに障害が発生した場合、それらの変更はすべて無視されます。
相互に関連のある変更のまとまりを「トランザクション」と呼びます。 トランザクションのすべての変更がディスク上の本来の場所に書き込まれると、そのトランザクションはコミットされたことになり、ジャーナルから削除されます。 ジャーナルには、複数のトランザクションを格納できます。 ディスク上の本来の場所にすべてのトランザクションの変更をコピーすることを「ジャーナルをリプレイする」と言います。
|
重要:
トランザクションを含んでいるジャーナルボリュームにアクセスするインプリメンテーションは、ボリュームへのアクセスを拒否するか、ジャーナルをリプレイしてボリュームの一貫性を確保します。 ボリュームヘッダーの lastModifiedVersion フィールドが、ジャーナルの使用と更新に正しく対応することが知られているインプリメンテーションのシグネチャに一致しない場合、そのジャーナルをリプレイしてはなりません(ディスク上の構造に一致しなくなっている可能性があり、リプレイすると構造が破壊されるかもしれません)。
|
ジャーナルデータ構造の概要
ボリュームヘッダの attributes フィールドの kHFSVolumeJournaledBit がセットされている場合、ボリュームにはジャーナルがあります。 データ構造は、ジャーナル情報ブロック、ジャーナルヘッダー、およびジャーナルバッファで構成されます。 ジャーナルブロックは、ジャーナルヘッダーとジャーナルバッファの場所とサイズを示します。 ジャーナルバッファは、トランザクションを格納するための領域です。 ジャーナルヘッダーは、ジャーナルのどの部分がアクティブで、コミット待ちのトランザクションが格納されているかを示します。

図 7. HFS Plus ジャーナルの概要
HFS Plus ボリュームでは、ジャーナル情報ブロックはファイルとして格納されています(カタログレコードおよびアロケーションビットマップで、その領域をきちんと表せるように)。 ファイルの名前は、".journal_info_block" で、ボリュームのルートディレクトリに格納されています。 ジャーナルヘッダーとジャーナルバッファは一緒に、".journal" という名前の別のファイルに格納されており、これもボリュームのルートディレクトリにあります。 これらのファイルはディスク上では連続しています(エクステントを 1 つだけ占有します)。 ジャーナルを使用するインプリメンテーションは、ファイルが通常のファイルとしてアクセスされないようにする必要があります。
|
注意:
インプリメンテーションは、ファイル名ではなく、ボリュームヘッダーの journalInfoBlock フィールドを使用してジャーナルブロックを見つけ出さなければなりません。 同様に、インプリメンテーションは、ファイル名ではなく、ジャーナル情報ブロックの内容に基づいて、ジャーナルヘッダーとジャーナルバッファを見つけ出さなければなりません。
|
1 つのトランザクションは、書き込むデータとデータの書き込み先となる場所を含む複数のブロックで構成されます。 これはディスク上に、ブロックの数とサイズを示すブロックリストヘッダーと、その直後に続くブロックの内容として表されます。

図 8. 単純なトランザクション
ブロックリストヘッダーのサイズは限られているので、1 つのトランザクションが複数のブロックリストヘッダーと、対応するブロックの内容で構成されることがあります(1 つのブロックリストヘッダーに、そのヘッダーが表すブロックの内容が続き、次のブロックリストヘッダーとそのブロック内容が続き、以降同様です)。 block_info の next フィールドの値がゼロ以外であれば、次のブロックリストヘッダーは同じトランザクションの続きです。

図 9. 複数ブロックリストで構成されるトランザクション
ジャーナルバッファは、循環バッファとして扱われます。 ジャーナルバッファからの読み取り時またはバッファへの書き込み時に、入出力処理はジャーナルバッファの末尾で停止し、(循環して)ジャーナルヘッダーの直後の位置から再開しなければなりません。 ブロックリストヘッダーおよびブロックの内容はこのように循環できます。 ジャーナルバッファは、一度に一部のみがアクティブになります。そのアクティブな部分は、ジャーナルヘッダーの start および end フィールドによって示されます。 アクティブでない部分のジャーナルバッファには意味のあるデータはなく、無視しなければなりません。
start が end と同じというあいまいな状態を防ぐために、ジャーナルは完全にいっぱいになる(ジャーナルバッファ全体がブロックリストとブロックによって占有される)ことが許されていません。 ジャーナルが完全にいっぱいになり、start が jhdr_size と等しくなければ、end は start と等しくなります。 そうなると、空のジャーナルといっぱいのジャーナルの区別がつきません。
ジャーナルが空でない(トランザクションを含んでいる)場合、ジャーナルをリプレイして、ボリュームの一貫性を保証します。 つまり、各トランザクションのデータをディスク上の正しいブロックに書き込む必要があります。
ジャーナル情報ブロック
ジャーナル情報ブロックは、ジャーナルヘッダーとジャーナルバッファの格納場所を示します。 ジャーナル情報ブロックは、ボリュームヘッダーの journalInfoBlock フィールドに番号が格納されているアロケーションブロックの先頭に格納されています。 ジャーナル情報ブロックは、JournalInfoBlock というデータ型を使用して表されます。
struct JournalInfoBlock {
UInt32 flags;
UInt32 device_signature[8];
UInt64 offset;
UInt64 size;
UInt32 reserved[32];
};
typedef struct JournalInfoBlock JournalInfoBlock;
|
それぞれのフィールドは次のような意味を持ちます。
flags- 1 ビットのフラグの集合が含まれています。 現在定義されているビットは以下に示します。 インプリメンテーションでは、未定義ビットを予約済みとして扱う必要があります。
device_signature- この領域は、ジャーナルがボリュームに格納されていない(
kJIJournalOnOtherDeviceMask がセットされている)場合に、ジャーナルが格納されているデバイスを表すために予約済みです。
offset- デバイスの先頭からジャーナルヘッダーの先頭までのオフセット(バイト単位)。 ジャーナルがボリューム上に格納さている(
kJIJournalInFSMask がセットされている)場合、このオフセットはボリュームの先頭からの相対位置となります。
size- ジャーナルヘッダーとジャーナルバッファを含むジャーナルのサイズ(バイト単位)。 このサイズには、ジャーナル情報ブロックは含まれません。
reserved- この領域は予約済みです。
次の定数は、flags フィールドに含まれるビットフラグを定義します。
enum {
kJIJournalInFSMask = 0x00000001,
kJIJournalOnOtherDeviceMask = 0x00000002,
kJIJournalNeedInitMask = 0x00000004
};
|
それぞれの値は次のような意味を持ちます。
kJIJournalInFSMask- セットされている場合、ジャーナルヘッダーとトランザクション用の領域はジャーナル対象ボリュームに格納されています。 ジャーナル情報ブロックの
offset フィールドは、ボリュームの先頭(アロケーションブロック番号ゼロ)からの相対位置となります
kJIJournalOnOtherDeviceMask- セットされている場合、ジャーナルヘッダーとジャーナルバッファ用の領域はジャーナル対象ボリュームにありません。 ジャーナル情報ブロックの
device_signature フィールドがジャーナルを含んでいるデバイスを示します。
kJIJournalNeedInitMask- ジャーナルヘッダーが無効で初期化する必要がある場合には、このビットをセットして示します。 このビットは、ジャーナルが最初に作成され、空間が割り当てられたときにセットされます。通常、ジャーナルボリュームを初めてマウントしたときにジャーナルヘッダーが初期化され、このビットがクリアされます。 このビットがセットされている場合、ジャーナルには有効なトランザクションはありません。
|
注意:
インプリメンテーションは現時点では kJIJournalInFSMask をセットする必要がありますが、kJIJournalOnOtherDeviceMask は必要ありません。 別のデバイスへのジャーナルの格納は現時点ではサポートされていません。 device_signature フィールドのフォーマットはまだ未定義です。
|
ジャーナルヘッダー
ジャーナルはジャーナルヘッダーから始まります。ジャーナルヘッダーの主な目的は、ジャーナルバッファ内のトランザクションの場所を記述することです。 ジャーナルヘッダーは journal_header データ型を使用して格納されます。
typedef struct journal_header {
UInt32 magic;
UInt32 endian;
UInt64 start;
UInt64 end;
UInt64 size;
UInt32 blhdr_size;
UInt32 checksum;
UInt32 jhdr_size;
} journal_header;
#define JOURNAL_HEADER_MAGIC 0x4a4e4c78
#define ENDIAN_MAGIC 0x12345678
|
それぞれのフィールドは次のような意味を持ちます。
magicJOURNAL_HEADER_MAGIC(0x4a4e4c78)という値が格納されています。 このフィールドは、ジャーナルヘッダーの整合性を確認するのに使用されます。endianENDIAN_MAGIC(0x12345678)という値が格納されています。 このフィールドは、ジャーナルヘッダーの整合性を確認するのに使用されます。start- ジャーナルヘッダーの先頭から最初(最も古い)トランザクションの先頭までのオフセット(バイト単位)。
end- ジャーナルヘッダーの先頭から最後(最新)トランザクションの先頭までのオフセット(バイト単位)。 このフィールドの値は
start フィールドの値より小さい値になりうることに注意してください。その場合それは、トランザクションがジャーナルの循環バッファの終わりに達して循環したことを示します。 end と start が同じ場合、ジャーナルは空で、リプレイするべきトランザクションがありません。
size- ジャーナルのサイズ(バイト単位)。 これには、ジャーナルヘッダーとジャーナルバッファも含まれます。 この値は、ジャーナル情報ブロックの
size フィールドの値と同じでなければなりません。
blhdr_size- ブロックリストヘッダーのサイズ(バイト単位)。 一般的には、4096 から 16384 の間となります。
checksum- ジャーナルヘッダーのチェックサム。後述の方法で計算されます。
jhdr_size- ジャーナルヘッダーのサイズ(バイト単位)。 ジャーナルヘッダーは自動的な更新が可能なように必ず 1 つのセクタを占有します。 したがって、この値はセクタサイズと同じです(たとえば、多くの光メディアでは 2048)。
ブロックリストヘッダー
ブロックリストヘッダーは、トランザクションに含まれるブロックのリストを示します。 トランザクションは、1 つのブロックリストで表せるよりも多くのブロックに変更を加える場合、複数のブロックリストを含むことが可能です。 ブロックリストヘッダーは、block_list_header 型の構造体に格納されます。
typedef struct block_list_header {
UInt16 max_blocks;
UInt16 num_blocks;
UInt32 bytes_used;
UInt32 checksum;
UInt32 pad;
block_info binfo[1];
} block_list_header;
|
それぞれのフィールドは次のような意味を持ちます。
max_blocks- 対象ブロックリストが表すことのできるブロック(
block_info 項目)の最大数。 このフィールドは、メモリ上にあるときに、ジャーナルバッファサイズを追跡するのに使用されます。 ディスク上では、このフィールドは予約済みとなります。
num_blocksbinfo 配列内の要素の数。 binfo 配列の最初の要素は、複数のブロックリストを 1 つのトランザクションとして連結するために使用されるので、データブロックの実際の数は num_blocks - 1 となります。
bytes_used- このブロックリストがジャーナルの中で占めるバイト数。ブロックリストには、ブロックリストヘッダーとリスト内の各ブロックのデータが含まれます。 次のブロックリストヘッダーがあれば、それは現在のブロックリストヘッダーの先頭から
bytes_used バイトの位置にあり、必要があればジャーナルバッファの終わりから循環して先頭に戻ります。
checksum- ブロックリストヘッダーのチェックサム。
binfo 配列の最初の要素を含みます(合計 32 バイトになります)。
pad- 境界合せ用のパディング。 インプリメンテーションでは、このフィールドを予約済みとして扱う必要があります。
binfo- 可変長サイズのブロックの配列。 配列には、
num_blocks+1 件のエントリがあります。 最初のエントリは、1 つのトランザクションが複数のブロックリストを占有し、前述のように next フィールドを使用する場合に使用されます。 残りの num_blocks エントリは、このブロックリストのデータがディスクのどこに書き込まれるかを示します。
binfo 配列の最初の要素は、トランザクションに追加のブロックリストが含まれるかどうかを示すために使用されます。 binfo 配列の他のそれぞれの要素は、ディスク上の正しい場所にコピーする必要がある、ジャーナルバッファ内の単独のデータブロックを表します。 それぞれのフィールドは次のような意味を持ちます。
typedef struct block_info {
UInt64 bnum;
UInt32 bsize;
UInt32 next;
} block_info;
|
bnum- ブロックないデータを書き込む必要のあるセクタの番号。 このフィールドが 0xFFFFFFFFFFFFFFFF である場合(全 64 ビットがセットされている場合)、このブロックをスキップして書き込みを行わないようにします。 このフィールドは、
binfo 配列の最初の要素のために予約済みです。
bsize- ジャーナルバッファから前述のセクタ番号にコピーするバイト数。 この値は 512 の倍数となります。 このフィールドは、
binfo 配列の最初の要素のために予約済みです。
next- このフィールドは、メモリ上にあるときに、複数のブロックリストをまたぐトランザクションを追跡するのに使用されます。 このフィールドがブロックリストの最初の
block_info でゼロの場合、トランザクションはこのブロックリストで終了となります。それ以外の場合、トランザクションには 1 つ以上の追加ブロックリストがあります。 このフィールドは、ブロックリスト配列の最初の要素が対象の場合にのみ意味があります。 ディスク上の実際の値は、ゼロまたは非ゼロをテストする以外に意味はありません。
ジャーナルチェックサム
ジャーナルヘッダーとジャーナルリストヘッダーはともに checksum フィールドを持っています。 これらのチェックサムは、これらの構造の基本的な一貫性チェックの一部として検証できます。 チェックサムを検証するには、checksum フィールドを一時的にゼロに設定し、calc_checksum ルーチンを呼び出して、対象となるヘッダーのアドレスとサイズを 渡します。 関数の結果は checksum フィールドの元の値と同じはずです。
static int
calc_checksum(unsigned char *ptr, int len)
{
int i, cksum=0;
for(i=0; i < len; i++, ptr++) {
cksum = (cksum << 8) ^ (cksum + *ptr);
}
return (‾cksum);
}
|
ジャーナルのリプレイ
ジャーナルをリプレイするには、インプリメンテーションはトランザクションをループル処理します。ループの中でトランザクションの個々のブロックをジャーナルからボリューム上の本来の場所にコピーします。 ブロックがすべてメディアに(単にドライバにではなく!)フラッシュされたら、インプリメンテーションはジャーナルヘッダーを更新してトランザクションを削除できます。
|
注意:
ジャーナルファイルをリプレイしても、オープンされているけれどもリンク解除されたファイルに対応する一時ファイルが削除されることは保証されていません。 ジャーナルのリプレイ後、これらの一時ファイルを削除できます。
|
次に、ジャーナルのリプレイ手順を示します。
- ボリュームヘッダーを変数
vhb に読み込みます。 ボリュームに HFS ラッパーがある場合があります。その場合、そのラッパーを使用してボリュームヘッダーの場所を特定します。
- ボリュームヘッダーの
attributes フィールドの kHFSVolumeJournaledBit をテストします。 セットされていなければ、リプレイするべきジャーナルはないので、処理を終了します。
- アロケーションブロック番号
vhb.journalInfoBlock からジャーナル情報ブロックを変数 jib に読み取ります。
jib.flags において kJIJournalNeedsInitMask がセットされている場合、ジャーナルは初期化されたことがないので、リプレイするべきジャーナルはありません。jib.flags の kJIJournalInFSMask がセットされていて kJIJournalOnOtherDeviceMask がクリアされていることを確認します。- ボリュームの先頭から
jib.offset バイトの位置にあるジャーナルヘッダーを読み取り、変数 jhdr に入れます。
jhdr.start と jhdr.end が同じ場合、ジャーナルにはトランザクションはないので、リプレイするべきものがありません。- ジャーナル内でのカレントオフセット(一般にはローカル変数)をジャーナルバッファの先頭
jhdr.start に設定します。
jhdr.start が jhdr.end が同じでない間、次のステップを実行します。
- ジャーナルのカレントオフセットから
jhdr.blhdr_size バイトのブロックリストヘッダーを変数 blhdr に読み取ります。
bhdr.binfo[1] から bhdr.binfo[blhdr.num_blocks] までのブロックごとに(両端を含む)、ジャーナルのカレントオフセットから bsize バイト分をボリューム上の bnum 番目のセクタにコピーします(バイトオフセット bnum*jdhr.jhdr_size に)。 jhdr_size はバイト単位でのセクタのサイズです。bhdr.binfo[0].next がゼロだったら、現在のトランザクションの最後のブロックリストが終了です。jhdr.start をジャーナルのカレントオフセットに設定します。
|
注意:
ジャーナルが循環バッファであることを忘れないでください。 ジャーナルバッファからブロックリストヘッダーまたはブロックを(前述のループの中で)読み取る際に、ジャーナルバッファの終わりに達して先頭に循環しないか確認する必要があります。 ジャーナルバッファを超える場合には、ジャーナルバッファの終わりで読み取りを停止し、ジャーナルバッファの先頭(ジャーナルの先頭からオフセット jhdr.jhdr_size バイトの位置)に戻って読み取りを再開しなければなりません。
|
トランザクション全体(ブロックリスト内のすべてのブロック。bhdr.binfo[0] がゼロ)をリプレイしたら、あるいは、すべてのトランザクションをリプレイしたら、ジャーナルヘッダーの start フィールドをジャーナル内のカレントオフセットに更新することができます。 更新すると、対象のブロックリストがディスクの正しい場所に書き込まれたことになるので、ジャーナルからは削除されます。
|
警告:
ジャーナルヘッダーのディスク上 start フィールドを更新する前に、それまでのブロック書き込みを確実に完了させる必要があります。 1 つの方法は、デバイスドライバに対してフラッシュ命令を発行し、デバイスドライバがすべてのダーティブロックを書き出すまで待ち、その後、デバイス自身をフラッシュしてデバイスがすべてのダーティブロックをメディアに書き込むまで待つという方法です。
|
先頭に戻る
HFSX
HFSX は HFS Plus への拡張であり、HFS Plus と互換性のない追加機能を可能にします。 現時点で定義されているそのような機能は、唯一、ファイル名の大文字小文字の区別だけです。
HFSX ボリュームの場合、ボリュームヘッダーの signature フィールドに 'HX'(0x4858)というシグネチャが入っています。 version フィールドは、ボリューム上で使用されている HFSX のバージョンを示します。現時点で定義されている唯一の値は 5 です。 従来のバージョンとの互換性のない機能(つまり、従来のバージョンからボリュームに安全にアクセスしたり、ボリュームを変更したりするのを妨げる新機能)が追加された場合、別の version 番号が使用されます。
|
注意:
新しい signature を採用する必要があったのは、一部のユーティリティが version フィールドを正しく使用していないためです。 これらのユーティリティは、あらかじめ文書化されていない version 値に遭遇すると、当該ボリュームの使用または修復(version フィールドの変更も含む)を試みます。
|
|
警告:
インプリメンテーションの中で、未知の version 値を持つ HFSX ボリュームに遭遇した場合には、当該ボリュームへのアクセスや修復を試みてはなりません。 破壊的なデータ喪失が生じる可能性があります。 特に、version フィールドの変更は絶対にしないでください。
|
将来のバージョンの HFSX 機能では、結果として新しいボリューム属性ビットを定義し、それらのビットを通じてボリュームでどの機能が使用されているかを示すことが計画されています。
HFSX ボリュームには、決して HFS ラッパーが存在することはありません。
アップルのパーティションマップにおいては、HFSX ボリュームのパーティションタイプ(PMPartType)は、「Apple_HFSX」に設定されます。
HFSX バージョン 5
Mac OS X 10.3 から導入された HFSX バージョン 5 では、ファイルとディレクトリの名前の大文字と小文字が区別されます。 名前の大文字小文字が区別されると、同時に同じディレクトリに、大文字小文字が異なるだけの同じ名前を持つ 2 つのオブジェクトが存在することが可能です。 たとえば、同じディレクトリに、「Bob」、「BOB」、および「bob」が存在することが可能です。
HFSX ボリュームでは、大文字小文字を区別することもしないことも可能です。 大文字小文字の区別の有無はボリューム全体に適用されます。つまり、どちらかの設定がボリューム上のすべてのファイルとディレクトリに適用されます。 HFSX ボリュームで大文字小文字が区別されるかどうかを知るには、カタログファイルの B ツリーヘッダーの keyCompareType フィールドを使用します。 値が kHFSBinaryCompare であれば、ボリュームでは大文字小文字が区別されます。 値が kHFSCaseFolding であれば、ボリュームでは大文字小文字が区別されません。
|
注意:
HFSX ボリュームで大文字小文字が区別されるとみなしてはなりません。 必ず keyCompareType を使用して大文字小文字の区別の有無を調べてください。
|
大文字小文字を区別しない HFSX ボリューム(keyCompareType が kHFSCaseFolding)は、HFS Plus と同じ Unicode 文字列比較アルゴリズムを使用します。
大文字小文字を区別する HFSX ボリューム(keyCompareType が kHFSBinaryCompare)は、単純に名前の各文字を 16 ビットの符号なし整数として比較します。 最初に異なった文字(文字列の先頭からのオフセットが最も小さいもの)に応じて相対的な順番が決まります。 文字の値が数値として小さいほうの文字列が、値が大きいほうの文字列よりも先になります。 たとえば、文字列「Bob」は、「apple」よりも先になります。なぜなら、文字「B」(10 進で 66)のコードが文字「a」(10 進で 97)のコードよりも小さいからです。
|
重要:
大文字小文字が区別される名前では Unicode の「無視可能」な文字は無視されません。 したがって、Unicode の比較規則では同等とみなされるけれども、大文字小文字が区別される HFSX ボリュームでは異なるとみなされる名前が 1 つのディレクトリに存在することが可能です。
|
|
注意:
ハードリンクで使用される「HFS+ Private Data」ディレクトリの名前にも使用されるヌル文字(0x0000)は、大文字小文字が区別される比較では先頭になり、区別されない比較では最後になります。
|
先頭に戻る
メタデータゾーン
Mac OS X バージョン 10.3 から、ファイルの領域を割り当てる場所を決めるための新しいポリシーを導入されました。このポリシーによって、大半のユーザにとってパフォーマンスが向上します。 このポリシーでは、ボリュームのメタデータと頻繁に使用される小さいファイル(「ホットファイル」)をディスク上の互いに近いところに置くことで、典型的なアクセスのシーク時間を削減します。 ディスク上のこの領域を「メタデータゾーン」と呼びます。
ボリュームのメタデータは、ファイルシステムによるボリュームの内容の管理を可能にする構造です。 メタデータには、アロケーションビットマップファイル、エクステントオーバーフローファイル、カタログファイル、およびジャーナルファイルが含まれます。 ボリュームヘッダーおよび代替ボリュームヘッダーもメタデータですが、その場所はボリューム内で固定されているため、ホットフィル領域にはありません。 Mac OS X では、クォータユーザファイルおよびクォータグループファイルを使用してボリューム上のディスク領域クォータを管理することができます。 これらのファイルは厳密にはメタデータではありませんが、OS が多用し、通常のホットファイルとして考えるには大きすぎるので、メタデータゾーンに含まれています。
インプリメンテーションでは、メタデータゾーンのポリシーに干渉しないことが求められます。 たとえば、ディスクを最適化する機能は、頻繁に使用することが分かっているファイルでなければ、ファイルをメタデータゾーンに移動するべきではありません。頻繁に使用するファイルは、「ホットファイル」リストに追加することができます。 同様に、メタデータゾーンのファイルは、ホットリストからも削除しない限り、ディスク上の他の場所に移動するべきではありません。
このポリシーは、サイズが少なくとも 10GB で、ジャーナリングが有効になっているボリュームにのみ適用されます。 メタデータゾーンは、ボリュームのマウント時に確立されます。 ゾーンのサイズは、次のサイズに基づいて決まります。
| 項目 |
メタデータゾーンい加算されるサイズ |
| アロケーションファイル |
アロケーションビットマップファイルの物理サイズ(totalBlocks にボリュームのアロケーションブロックのサイズを乗じた値) |
| エクステントオーバーフローファイル |
4MB のほかに、100GB ごとに 4MB(最大 128MB まで) |
| ジャーナルファイル |
8MB のほかに、100GB ごとに 8MB(最大 512MB まで) |
| カタログファイル |
1 KB につき 10 バイト(最小 1GB) |
| ホットファイル |
1 KB につき 5 バイト(最小 10MB、最大 512MB) |
| クォータユーザファイル |
後述参照 |
| クォータグループファイル |
後述参照 |
Mac OS X バージョン 10.3 では、アロケーションファイル用に確保されている領域は実のところ、ボリュームのアロケーションファイルの最小サイズです(アロケーションブロックの合計数を 8 で割り、アロケーションブロックサイズの倍数に切り上げます)。 アロケーションファイルがそれよりも大きいと(ボリュームを後で拡大しやすくするために、時々そのようになっていることがあります)、他のメタデータおよびメタデータゾーン内のホットファイルで利用できる領域が少なくなります。 これはバグです(r. 3522516)。
それぞれのタイプのメタデータ(アロケーションビットマップファイルを除く)のために確保されている領域のサイズは、ボリュームの合計サイズに基づいています。 これらを算出するために、ボリュームの合計サイズは、アロケーションブロックサイズにアロケーションブロックの合計数を乗じた値となっています。
クォータユーザファイルおよびクォータグループファイル用に確保されているサイズは、複雑な計算から求められます。 それぞれについて、確保されるサイズは、(items + 1) * 64 という式から算出されるバイト数です。ここで、items はボリュームのサイズをギガバイト単位で切り捨てた値に基づきます。 クォータユーザファイルの場合、items は、1 ギガバイト当たり 256 を 2 のべき乗に切り上げた値で、最小値は 2048、最大値は 2097152(2M)です。 クォータグループファイルの場合、items は、1 ギガバイト当たり 32 を 2 のべき乗に切り上げた値で、最小値は 2048、最大値は 262144(256K)です。 クォータファイルはホットファイルとみなされ、通常ホットファイルとして認定できるファイルの最大サイズよりも大きいけれども、ホットファイル領域に置かれます。
メタデータゾーンの合計サイズは、上記のサイズの合計を、メタデータゾーンをボリュームビットマップにおいてアロケーションブロックの整数倍の領域として表すことができるサイズに切り上げたサイズです。 つまり、メタデータゾーンの最初と最後が、ボリュームビットマップのアロケーションブロックの境界に整合するということです。 したがって、メタデータのサイズはアロケーションブロックサイズの 2 乗の 8 倍の倍数に切り上げられます。 Mac OS X バージョン 10.3 では、メタデータゾーンのサイズの切り上げの結果として生じた余剰スペースは、カタログとホットファイル領域の間で分割されます(それぞれ 2/3 と 1/3)。
エクステントオーバーフローファイルとジャーナルファイルのサイズは、ボリュームの合計サイズを 100GB で割って、切捨てを行うことで求めます。 その値に 1 を加算します(切捨ての結果として失われた残り部分を補填するため)。 その結果に、それぞれ 4MB と 8MB を乗じます。 ボリュームの合計サイズが 100GB の倍数でない場合、これは 100GB ごとに 4MB(または 8MB)の値を切り上げた値となります。
Mac OS X バージョン 10.3 では、メタデータゾーンはボリュームの先頭のボリュームヘッダーに続く位置にあります。 ホットファイル領域は、メタデータゾーンの終わりにあります。
通常のファイル割り当てを行う際には、メタデータゾーンはスキップされます。 これによって、メタデータの断片化が少なくなり、すべてのメタデータがディスク上の同じ領域にあることが保証されます。 メタデータゾーンの外の領域が使い果たされると、通常のファイルの割り当ての際にもメタデータゾーン内の領域も使用されるようになります。 同様に、メタデータの領域を割り当てる際には、メタデータゾーン内の領域がから先に使用されます。 メタデータゾーンの領域が使い果たされると、メタデータの割り当ての際にメタデータゾーン外の領域も使用されるようになります。
ホットファイル
ディスク上のほとんどのファイルは、アクセスされることがあったとしても、まれです。 また、最も頻繁に使用される(ホットな)ファイルは小型です。 これらの小型の頻繁にアクセスされるファイルは、パフォーマンスを向上するために、ボリュームのメタデータに近い場所、メタデータゾーンの中に移動されます。 これによって、大半のアクセスのシーク時間が減少します。 ファイルがメタデータゾーンに移される際には、断片化も解消されるので(単独のエクステントに割り当てられます)、それもパフォーマンスのさらなる向上に寄与します。 個の処理を「適応ホットファイルクラスタリング」と呼びます。
頻繁に使用される(ホット)ファイルの間の相対的な重要度は「温度」と呼ばれます。 最も温度の高い(大きい)ファイルが、メタデータゾーンに実際に移動されるファイルとなります。 Mac OS X バージョン 10.3 では、ファイルの温度は、測定期間中にファイルから読み取られたバイト数をファイルのバイト単位のサイズで割ることによって算出されます。 これが、ファイルが読み取られている頻度を示す値となります。
このセクションでは、ホットファイルの追跡に使用されるディスク上の構造を説明します。 実行時に使用されるアルゴリズムは変更される可能性があり、ここには記載しません。
メタデータゾーン内のホットファイル領域へのファイルの移動とそこからの移動は、ユーザの実際のファイルアクセスパターンに基づく緩やかなプロセスです。 ファイルの移動はいくつかの段階に分かれて生じます。
- 測定
- 最も頻繁にアクセスされるファイルを知るためにファイルアクセスを監視する
- 評価
- 細菌使用されたホットファイルを以前に見つかったホットファイルと統合する
- 追い出し
- 古い使用頻度が低くなったホットファイルをメタデータゾーンの外に移動して、新しいもっと温度の高いファイルのための場所を空ける
- 取り込み
- 新しいもっと温度の高いファイルをメタデータゾーンに移動する
ホットファイルの B ツリー
メタデータゾーンのホットファイル領域に現在あるファイルを追跡するために B ツリーが使用されます。 ホットファイルの B ツリーはボリューム上の通常のファイルです(つまり、カタログにレコードがあります)。 ルートディレクトリに、「.hotfiles.btree」という名前で存在しています。 このファイルを偶発的に操作してしまわないように、Finder 情報の finderFlags フィールドの kIsInvisible ビットと kNameLocked ビットをセットしておく必要があります。
ホットファイルの B ツリーのノードサイズは少なくとも 512 バイトで、通常はボリュームのアロケーションブロックサイズと同じです。 HFS Plus ボリューム上の他の HFS Plus ボリュームと同様に、キー長フィールドは 16 ビットで、B ツリーのヘッダーの attributes の kBTBigKeysMask がセットされています。 ヘッダーレコード内の btreeType は、 kUserBTreeType に設定しておく必要があります。
この B ツリーのユーザデータレコードには、ホットファイルの測定に関する情報が格納されています。 ユーザデータのフォーマットは、 HotFilesInfo 構造体によって記述されます。
#define HFC_MAGIC 0xFF28FF26
#define HFC_VERSION 1
#define HFC_DEFAULT_DURATION (3600 * 60)
#define HFC_MINIMUM_TEMPERATURE 16
#define HFC_MAXIMUM_FILESIZE (10 * 1024 * 1024)
char hfc_tag[] = "CLUSTERED HOT FILES B-TREE ";
struct HotFilesInfo {
UInt32 magic;
UInt32 version;
UInt32 duration; /* サンプリング期間の長さ */
UInt32 timebase; /* 測定期間の開始時間 */
UInt32 timeleft; /* 測定期間の終了時間 */
UInt32 threshold;
UInt32 maxfileblks;
UInt32 maxfilecnt;
UInt8 tag[32];
};
typedef struct HotFilesInfo HotFilesInfo;
|
それぞれのフィールドは次のような意味を持ちます。
magicHFC_MAGIC(0xFF28FF26)という値を格納する必要があります。versionHotFilesInfo 構造体のバージョンが格納されます。 ここでは構造体のバージョン 1 を説明しています。 インプリメンテーションで他のバージョンに遭遇した場合には、ホットファイルの B ツリーを読み取りも変更もしてはなりません。duration- 現在の測定フェーズの秒単位の長さを示します。 Mac OS X 10.3 では、この値は通常、
HFC_DEFAULT_DURATION(60 時間)です。
timebase- 現在の測定フェーズが開始された時間を示します。GMT 時間の 1970 年 1 月 1 日から経過秒数で表されます。
timeleft- 現在の測定フェーズの残り時間の秒単位の長さを示します。
threshold- ホットファイル領域に移動するファイルとして認定できる最低温度を示します。 この値をよりも低い温度のファイルは、ホットファイル領域の外に出されます。
maxfileblks- ホットファイル領域に移動するファイルとして認定できる最大ファイルサイズをアロケーションブロック単位で示します。 このサイズを超えるファイルは、ホットファイル領域には移されません。 Mac OS X 10.3 では、この値は通常、
HFC_MAXIMUM_FILESIZE をボリュームのアロケーションブロックサイズで割った値です。
maxfilecnt- ホットファイル領域に置くファイルの最大数を示します。 ホットファイル領域には、この値よりも多くのファイルが含まれている場合があることに注意してください。測定フェーズが始まる前にすでにホットファイル領域に存在していた場合には特にそうなり得ます。 この数字は、ホットファイル測定機能が追跡を計画して最終的にはホットファイル領域に入れることになるファイルの数を示します。
tag"CLUSTERED HOT FILES B-TREE "というヌル終了(C 言語形式)ASCII テキスト文字列が格納されます(両端の二重引用符は除く)。 なお、最後の 6 バイトは、5 つのスペース文字と 1 つのヌル(ゼロ値)バイトです。 このフィールドは、デバッグ時あるいはディスクエディタ使用時に、ホットファイル B ツリーを判別しやすくするためにあります。 インプリメンテーションでは、このフィールドを検証したり変更したりしてはなりません。
ホットファイルのレコードキー
ホットファイルの B ツリーのキーは、HotFileKey という型です。
struct HotFileKey {
UInt16 keyLength;
UInt8 forkType;
UInt8 pad;
UInt32 temperature;
UInt32 fileID;
};
typedef struct HotFileKey HotFileKey;
#define HFC_LOOKUPTAG 0xFFFFFFFF
#define HFC_KEYLENGTH (sizeof(HotFileKey) - sizeof(UInt32))
|
それぞれのフィールドは次のような意味を持ちます。
keyLength- ホットファイルキーの長さ。
keyLength フィールドの長さは含みません。 ホットファイルキーの長さは固定です。 このフィールドは、10 という値を持っています。
forkType- フォークがデータフォーク(値は
0x00)またはリソースフォーク(値は 0xFF)のどちらとして追跡されているかを示します。 Mac OS X バージョン 10.3 では、ホットファイル領域にはデータフォークのみ置くことができます。
pad- インプリメンテーションでは、これをパディングフィールドとして扱う必要があります。
temperature- フォークの温度。 ホットファイルのスレッドレコードの場合、このフィールドには
HFC_LOOKUPTAG(0xFFFFFFFF)という値が格納されます。
fileID- 追跡対象ファイルのカタログノード ID。
ホットファイルのキーはまず temperature によって比較され、さらに fileID、最後に forkType によって比較されます。 これらの比較はすべて符号なしで行われます。
ホットファイルレコード
カタログファイルの場合と同様に、ホットファイルの B ツリーには 2 種類のレコードが格納されます。 すなわち、ホットファイルレコードとスレッドレコードです。 ホットファイル領域のフォークはすべて、ホットファイル B ツリーにホットファイルレコードとスレッドレコードの両方があります。 ホットファイルレコードは、ホットファイルを温度に基づいて探すときに使用されます。 スレッドレコードは、ホットファイルをカタログノード ID とフォークのタイプに基づいて探すときに使用されます。
ホットファイル B ツリー内のスレッドレコードは、キーの temperature の中で特別な値(HFC_LOOKUPTAG)を使用します。 スレッドレコードのデータは、当該フォークの temperature を UInt32 として格納した値です。 したがって、カタログノード ID とフォークタイプがあれば、フォークのスレッドレコードのキーを作成することが可能です。 スレッドレコードが存在する場合には、スレッドのデータから温度を取得してホットファイルレコードのキーを作成できます。 スレッドレコードが存在しない場合、フォークはホットファイルとして追跡されていません。
ホットファイルレコードは前述のようにすべてのキーフィールドを使用します。 ホットファイルレコードのデータは 4 バイトです。 ホットファイルレコード内のデータには意味はありません。 デバッグを支援するために、Mac OS X バージョン 10.3 では通常、ファイル名の先頭の 4 バイト(UTF-8 でエンコード)または "????" という ASCII テキストを格納します。
インプリメンテーションがホットファイルの温度を変更した場合には、古いホットファイルレコードを削除し、新しい温度の新しいホットファイルを挿入し、スレッドレコードのデータを変更して新しい温度を含める必要があります。
ホットファイルの温度の測定
測定フェーズでは、一定期間にわたってファイルの使用状況に関する情報を収集します。 有効な統計情報を収集するために、測定フェーズは、特定のマウントの存続時間よりも長く保つことができます。 したがって、使用状況に関する情報は、時間の経過に伴って累積できるようにディスク上に保存されます。
フォークデータ構造体の clumpSize フィールドに、フォークから実際に読み取られたデータの量が記録されます。 フィールドの長さが 32 ビットに限定されているので、ここにはファイルから読み取られたアロケーションブロックの数が格納されます。 フォークの温度は、その clumpSize を totalBlocks で割ることによって算出できます。
先頭に戻る
Unicode に関する微妙な問題
HFS Plus では、ファイルおよびフォルダ名を格納するために Unicode 文字列を多用します。 ただし、Unicode は現在も発展を続けているテクノロジーであるため、ファイルシステム内で Unicode を使用することにはいくつかの挑戦が伴います。 このセクションでは、HFS Plus によって使用されるソリューションとともに、これらいくつかの挑戦についても説明します。
|
重要:
インプリメンテーションで使用する Unicode ユーティリティのアルゴリズムがここで定義する HFS Plus のアルゴリズムと等価ではなく、将来にわたってもそのようになる保証がない場合は、分解と比較を行うために、そのネイティブプラットフォームによってインプリメントされている Unicode ユーティリティを使用する必要はありません。 ただし、このようなケースはごくまれです。 プラットフォームのアルゴリズムは Unicode 規格とともに発展する傾向があります。 しかし HFS Plus のアルゴリズムが発展する可能性はありません。もしこのようなことを行えば、既存の HFS Plus ボリュームとの互換性が失われてしまいます。
|
|
注意:
Mac OS の Text Encoding Converter は、HFS Plus ボリューム上に格納されている標準の分解された形式との間の変換を可能にするいくつかの定数を提供しています。 CreateTextEncoding を使ってテキストエンコーディングを作成するときは、TextEncodingBase に kTextEncodingUnicodeV2_0、TextEncodingVariant に kUnicodeCanonicalDecompVariant、そして TextEncodingFormat に kUnicode16BitFormat を設定してください。 これらの値を使用することで、Unicode の規格が発展していっても、HFS Plus ボリューム上の形式と同じ形式が保たれることが保証されます。
|
標準的な分解
Unicode では、同じ文字の並びを複数の同等の形式で表せる場合があります。 たとえば、「 」という文字は、単独の Unicode 文字 u+00E9(latin small letter e with acute)または、2 つの Unicode 文字 u+0065 および u+0301(the letter "e" plus a combining acute symbol)として表せます。 」という文字は、単独の Unicode 文字 u+00E9(latin small letter e with acute)または、2 つの Unicode 文字 u+0065 および u+0301(the letter "e" plus a combining acute symbol)として表せます。
B ツリーキーの比較ルーチン(Unicode 文字列を比較する)の複雑さを緩和するために、HFS Plus では Unicode 文字を完全に分解した形式にして、合成文字を標準の順番で格納することを規定しています。 その他の等価形式はHFS Plus文字列としては不正です。 インプリメンテーションでは、文字列をディスクに格納する前に、これらの等価な形式を完全に分解された形式に変換する必要があります。
Unicode分解テーブルには、HFS Plus文字列のとしては不正な文字のリストと、それらの代わりに使用する必要のある等価文字が含まれています。 「Illegal」というタイトルの列に現れる文字は、そのすぐ右側にある列(「Replace With」というタイトルの列)の文字に置き換える必要があります。
|
注意:
Mac OS バージョン 8.1 から 10.2.x にかけては Unicode 2.1 に基づく分解を使用します。 Mac OS バージョン 10.3 からは Unicode 3.2 に基づく分解を使用します。 分解方式が変わった大半の文字は、Mac のどのエンコーディングでも使用されていないので、HFS Plus ボリュームに現れる可能性は低いです。 分解方式の変更が最も多かったのは、MacGreek エンコーディングです。
前述の Unicode 分解テーブルに、Unicode 2.1 および Unicode 3.2 の間で追加、削除、変更のあった分解を明示しています。
|
また、u+AC00 から u+D7A3 の範囲のコードを持つハングル文字は不正であり、Unicode 2.0 のセクション 3.10 で説明されているように、結合字母の等価なシーケンスを使って置き換える必要があります。
|
重要:
u+2000からu+2FFFの範囲のコードを持つ文字は句読点、記号、絵文字、矢印、図形などです。 たとえば、u+24xxのブロックは「(a)」のような特殊文字を表す単一の文字を含んでいます。 この範囲の文字は完全に分解されません。 これらの文字はHFS Plus文字列の中で変更されずにそのまま残ります。 これにより、情報を失うことなくMac OSエンコーディング文字列とUnicodeとの間で相互に変換を行うことが可能になります。 ユーザがファイル名の中で digbat の 「(a)」 が 「(」、「a」、「)」 という 3 つの文字の並びと等価だと必ずしも期待するわけではないので、不自然ではありません。
u+F900 から u+FAFF にかけての文字は CJK 互換表意文字であり、HFS Plus 文字列では分解されません。
|
したがって、先に示した例の「 」は、2 つの Unicode 文字 u+0065 および u+0301 として(この順番で)格納する必要があります。 Unicode 文字 u+00E9 は、HFS Plus B ツリーキーの一部として使用される Unicode 文字列に現れてはなりません。 」は、2 つの Unicode 文字 u+0065 および u+0301 として(この順番で)格納する必要があります。 Unicode 文字 u+00E9 は、HFS Plus B ツリーキーの一部として使用される Unicode 文字列に現れてはなりません。
大文字小文字を区別しない文字列比較アルゴリズム
HFS Plus の大文字小文字が区別されない HFSX では、文字列の比較も大文字小文字を区別せずに行う必要があります。 Unicode 規格では、大文字と小文字の間に何らかの対応関係があることは示唆しても、それらの対応関係を厳密には定義していません。 HFS Plus の文字列比較アルゴリズム(以下に示す)には具体的な大小文字の対応関係の定義が含まれています。 インプリメンテーションでは、このアルゴリズムによって表現されている対応関係を使用する必要があります。
さらに、Unicode は文字列を比較するときに特定のフォーマット文字を無視(スキップ)することを要求します。 大小文字の対応関係に使用されるアルゴリズムとテーブルもこれらの文字を無視します。 インプリメンテーションでは、このアルゴリズムによって無視される文字を無視する必要があります。
|
注意:
大文字小文字が区別される HFSX ボリュームでは、Unicode の無視可能文字は無視されません。 これらの文字は、大文字小文字が区別される HFSX における名前の比較では意味を持ちます。
|
HFS Plus の大文字小文字を区別しない文字列比較ルーチンは、以下に示す FastUnicodeCompare ルーチンによって定義されています。 このルーチンは、文字列を相対的に配列する方法、つまり先頭の文字列が 2 番目の文字列よりも小さいか、大きいか、あるいは両方の文字列が等しいかを呼び出し元に通知する値を返します。 HFS Plus のインプリメンテーションでは、このルーチンを直接的に使用してもかまいませんが、同様の相対的な配列を生成する別のルーチンを使用することもできます。
|
注意:
HFS Plus 文字列としては不正であるため、FastUnicodeCompare ルーチンは合成された Unicode 文字を処理しません。 「標準的な分解」で説明したように、すべての HFS Plus 文字列は完全に分解した形式にして、合成文字が標準的な順序で並んでいる必要があります。
|
/*
FastUnicodeCompare - 2 つの Unicode 文字列を比較する。
相対的な順番を返す。
条件 結果
--------------------------
str1 < str2 => -1
str1 = str2 => 0
str1 > str2 => +1
小文字のテーブルは 256 のエントリ(オリジナルの Unicode 文字の各上位バイトに対して 1 つのエントリ)で始まる。
そのエントリがゼロの場合、その上位バイトを含むすべての
文字はすでに大小文字が折りたたまれている。エントリが
ゼロでない場合、それは、その上位バイトを含む文字に
対するサブテーブルの始点の _index_ (バイトオフセット
ではなく)。無視することのできるすべての文字は値ゼロに
折りたたまれている
疑似コード:
Let c = ソース Unicode 文字
Let table[] = 小文字テーブル
lower = table[highbyte(c)]
if (lower == 0)
lower = c
else
lower = table[lower+lowbyte(c)]
if (lower == 0)
この文字を無視
無視できる文字を処理するため、次に有効な文字を検出
するためのループが必要になる。また、比較する文字の数を
あらかじめ計算することはできない。つまり、文字列の
長さ が無視できない文字の数よりも長くなることもある。
さらに、文字列の先頭と末尾を含 めて、文字列内のどの位置でも
無視できる文字を処理できなければならない。ここでは、
ゼロ値を見張り番として使用し、文字列の末尾と無視
できる文字の両方を検出する。File Manager は
NULL 文字 (値ゼロ) がファイル名の一部となることを
妨げないため、大小文字のマッピングテーブルは u+0000 を
何からのゼロでない値 (無効な Unicode 文字である 0xFFFF
など) にマップすると見なされる
疑似コード:
while (1) {
c1 = GetNextValidChar(str1) -- 文字列の末尾であれば
-- ゼロを返す
c2 = GetNextValidChar(str2)
if (c1 != c2) break; -- 違いを検出した
if (c1 == 0) -- 両方の文字列で
-- 文字列の末尾に同時に達したか
return 0; -- もしそうであれば、文字列は等しい
}
-- ここに達していれば c1 != c2。したがって、
-- 単にどちらが小さいかを調べればよい
if (c1 < c2)
return -1;
else
return 1;
*/
SInt32 FastUnicodeCompare (
register ConstUniCharArrayPtr str1,
register ItemCount length1,
register ConstUniCharArrayPtr str2,
register ItemCount length2) {
register UInt16 c1,c2;
register UInt16 temp;
register UInt16* lowerCaseTable;
lowerCaseTable = gLowerCaseTable;
while (1) {
/* 有効な文字がなくなったときに備えて
c1、c2 のデフォルト値を設定しておく */
c1 = 0;
c2 = 0;
/* str1 から次の無視不能な文字を探す。
なければゼロを返す */
while (length1 && c1 == 0) {
c1 = *(str1++);
--length1;
/* この上位バイトに対する
サブテーブルが存在するか */
if ((temp = lowerCaseTable[c1>>8]) != 0)
/* もし存在すれば、文字を折りたたむ */
c1 = lowerCaseTable[temp + (c1 & 0x00FF)];
}
/* str2 から次の無視不能な文字を探す。
なければゼロを返す */
while (length2 && c2 == 0) {
c2 = *(str2++);
--length2;
/* この上位バイトに対する
サブテーブルが存在するか */
if ((temp = lowerCaseTable[c2>>8]) != 0)
/* もし存在すれば、文字を折りたたむ */
c2 = lowerCaseTable[temp + (c2 & 0x00FF)];
}
/* 違いを検出した場合はループを停止する */
if (c1 != c2)
break;
/* 同時に両方の文字列の
終わりに達したか */
if (c1 == 0)
/* 達している。したがって文字列は等しい */
return 0;
}
if (c1 < c2)
return -1;
else
return 1;
}
/* 小文字テーブルは 256 のエントリを含む上位バイトテーブルから構成され、その後に いくつかの 256 エントリサブテーブルが続く。
上位バイトテーブルには、その上位バイトを持つ文字に対応する
サブテーブルへのオフセットかゼロが含まれています。ゼロの場合、
当該ブロックに大文字小文字のマッピングまたは無視された文字が
なかったことを示す。無視された文字はゼロにマップされる。 */
UInt16 gLowerCaseTable[] = {
/* 上位バイトのインデックス( == 0 大小文字のマッピングおよび文字の
無視がない場合。簡略化のために完全なデータテーブルは省略する。
コードをダウンロードするための URL については「ダウンロード」
を参照。 */
};
|
先頭に戻る
HFS ラッパー
HFS Plus をサポートしないシステムに HFS ボリュームであるかのように見せるため、HFS Plus ボリュームが HFS ボリューム内に包含されている場合があります。 これには 2 つの重要な利点があります。
- ROM内に HFS(HFS Plus ではなく)サポートを含むコンピュータを HFS Plus ボリュームから起動できるようになります。 ラッパーを作成するとき、Mac OS は埋め込み HFS Plus ボリュームの検出とマウントに必要な最小限のコードを含む System ファイルを組み込み、その System ファイルからブートを継続します。
- HFS をサポートし、HFS Plus をサポートしていないコンピュータに HFS Plus ボリュームを挿入することで、ユーザの操作感を向上させることができます。 このようなコンピュータでは、HFS ラッパーは 1 つのボリュームとしてマウントされ、ボリュームに何らかの障害(空、破損している、あるいは読み込みができないなど)があるのではないかとユーザに混乱を招く可能性のあるエラーダイアログが表示されないようにします。 また、HFS ラッパーには、ユーザがファイルにアクセスするために必要な手順を説明する Read Me 書類が含まれていることもあります。
このセクションでは、HFS ラッパーがどのようにレイアウトされていて、HFS Plus ボリュームがどのようにラッパーの内部に埋め込まれているかを説明します。
|
重要:
このセクションでは HFS Plus ボリュームフォーマットについては説明しません。むしろ、HFS Plus ボリューム(またはその他のボリューム)を HFS ボリューム内に埋め込むことを可能にする HFS ボリュームフォーマットの追加機能について説明します。 ただし、すべての Mac OS ボリュームは HFS ラッパーを使ってフォーマットされるため、すべてのインプリメンテーションではラッパーを解析して、埋め込まれている HFS Plus ボリュームを検出できなければなりません。
|
|
注意:
HFS Plus ボリュームが HFS ラッパーを持つ必要はありません。 この場合、ボリュームはディスクの先頭から始まり、ボリュームヘッダーは 1024 バイトのオフセットに位置することになります。 ただし、現在のところ、Apple のソフトウェアは HFS ラッパーを使って、すべての HFS Plus ボリュームを初期化します。
|
HFS マスターディレクトリブロック
HFS ボリュームの 1024 バイトのオフセットには、常にマスターディレクトリブロック(MDB)が含まれます。 MDB は HFS Plus のボリュームヘッダーに似ています。 HFS ボリューム内に埋め込まれたボリュームをサポートするため、MDB のいくつかの未使用フィールドが変更され、埋め込みボリュームのタイプ、位置、およびサイズを示すために使用されるようになりました。
以前の drVCSize フィールド(オフセット 0x7C)は現在、drEmbedSigWord と呼ばれています。 この 2 バイトフィールドには、埋め込みボリュームのタイプを識別する一意の値が含まれます。 HFS Plus ボリュームが埋め込まれているとき、drEmbedSigWord は kHFSPlusSigWord('H+')でなければなりません。これは、HFS Plus ボリュームヘッダーの signature フィールドに格納されているのと同じ値です。
以前の drVBMCSize および drCtlCSize フィールド(オフセット 0x7E)は、4 バイトを占有する単一のフィールドに結合されました。 この新しい構造体は drEmbedExtent と呼ばれ、そのデータ型は HFSExtentDescriptor です。 この中には、埋め込みボリュームが始まる開始点のアロケーションブロック番号(startBlock)と、埋め込みボリュームが占有するアロケーションブロックの数(blockCount)が含まれます。 埋め込みボリュームは連続していなければなりません。 これら両方の値は、HFS Plus のアロケーションブロックではなく、HFS ラッパーのアロケーションブロックに関連しています。
|
注意:
「Inside Macintosh: Files」の HFS ボリュームの説明の中で、これらのフィールドはさまざまなキャッシュのサイズを格納するために使用されると記載されており、それぞれのフィールドのラベルには「内部的に使用される」と書かれています。
|
ディスク上で埋め込みボリュームの位置を実際に検出するため、インプリメンテーションでは MDB の drAlBlkSiz および drAlBlSt フィールドを使用する必要があります。 drAlBlkSiz フィールドには、HFS アロケーションブロックのサイズ(バイト単位)が含まれます。 また、drAlBlSt フィールドには、ブロックサイズを 512 バイトとして、ボリュームの先頭を起点としたラッパーのアロケーションブロック 0 のオフセットが含まれます。
|
重要:
このような埋め込みにより、HFS Plus ボリュームオフセットとディスクオフセットとの間の変換が導入されます。 HFS Plus ボリュームは現実のディスク内部に埋め込まれた仮想ディスク上に存在します。 埋め込みディスク上の HFS Plus 構造にアクセスするとき、インプリメンテーションでは埋め込みディスクのオフセットを HFS Plus の位置に加算する必要があります。 リスト 2 に、このような処理を行う具体的な方法を示します。ここでは、512 バイトのセクタを想定します。
|
static UInt32 HFSPlusSectorToDiskSector(UInt32 hfsPlusSector)
{
UInt32 embeddedDiskOffset;
embeddedDiskOffset = gMDB.drAlBlSt +
gMDB.drEmbedExtent.startBlock * (drAlBlkSiz / 512)
return embeddedDiskOffset + hfsPlusSector;
}
|
|
リスト 2 埋め込みボリュームに対するセクタの変換
|
HFS ラッパー内のファイルが誤って変更されるのを防ぐため、MDB の drAtrb(ボリューム属性)フィールドに含まれる kHFSVolumeSoftwareLockBit をセットして、ラッパーボリュームがソフトウェアによって書き込み保護になっていることをマークする必要があります。 正しい HFS インプリメンテーションはラッパーボリュームに変更が加えられないようにします。
HFS Plus ボリュームのパフォーマンスを向上させるため、ラッパーのアロケーションブロックのサイズは HFS Plus ボリュームのアロケーションブロックのサイズの倍数になっていなければなりません。 また、ラッパーのアロケーションブロックの起点(drAlBlSt)は HFS Plus ボリュームのアロケーションサイズの倍数(HFS Plus のアロケーションブロックがより大きい場合はおそらく 4KB の倍数)でなければなりません。 これらの推奨値にしたがうと、HFS Plus のアロケーションブロックは適切にディスク上に配置されます。 また、HFS Plus のアロケーションブロックサイズがセクタサイズの倍数になっていると、デバイスドライバレベルでのブロッキングとブロッキングの解除が最小限に抑えられます。
埋め込みボリュームに対する領域の割り当て
埋め込みボリュームによって占有される領域は、HFS ラッパーのボリュームビットマップ(HFS Plus のアロケーションファイルに類似した)の中で割り当て済みとマークされ、HFS ラッパーの不良ブロックファイル(HFS Plus の不良ブロックファイルに類似した)の中に置かれている必要があります。 これはそれらのブロックが実際に不良であるという意味ではありません。単に、HFS Plus ボリュームが HFS ラッパー内で新しく作成されたファイルによって上書きされたり、誤って削除されたり、または HFS ディスク修復ユーティリティによって使用可能な空き領域としてマークされるのを防ぐための措置にすぎません。
MDB の drAtrb(ボリューム属性)フィールドにある kHFSVolumeSparedBlocksMask ビットは、ボリュームが不良ブロックファイルを持つことを示すようにセットされていなければなりません。
Read Me と System ファイル
|
重要:
このセクションは HFS Plus ボリュームフォーマットの説明の一部ではありません。 ここでは、HFS Plus の既存の Mac OS インプリメンテーションが HFS ラッパーを作成する方法について説明します。 このセクションは、読者に関連情報を提供するためだけに用意されています。
|
Mac OS のディスク初期化パッケージによって初期化されるとき、HFS ラッパーボリュームのルートフォルダには次の 5 つのファイルが含まれます。
- Read Me - 実際には「Where_have_all_my_files_gone?」という名前を持つ Read Me ファイルには、このボリュームが実際には HFS Plus ボリュームであり、このコンピュータにはまだ HFS Plus がインストールされていないためボリュームの内容にアクセスできないことを説明するテキストが含まれています。 また、HFS Plus サポートをインストールするために必要な操作手順も説明されています。 また、システムソフトウェアのローカライズ版では、ローカライズされた名前を持つファイルとテキスト内容が作成されます。
- System および Finder(不可視ファイル)-- System ファイルには、埋め込み HFS Plus ボリュームを検出してマウントし、埋め込みボリューム内の System ファイルからブートを継続するために必要な最小限のコードが含まれています。 Finder ファイルは空であり、Finder の古いバージョンがラッパーのルートディレクトリを壊し、そのボリュームからブートできなくなるのを防ぐためにだけ存在します。
- Desktop DB および Desktop DF(不可視ファイル) -- Desktop DB および Desktop DF ファイルは、いわば人工的にラッパーボリューム上のファイルを作成するために必要なファイルです。
また、MDB の drFndrInfo(Finder 情報)フィールドの先頭にある SInt32 にフォルダ ID を格納することで、ルートフォルダは特別なフォルダとして設定されます。
先頭に戻る
ボリュームの一貫性のチェック
HFS Plus ボリュームは、相互に関連する複数の異なるデータ構造から構成される 1 つの複雑なデータ構造です。 これらのデータ構造の間に一貫性がないと、重大なデータ消失の原因になる場合があります。 HFS Plus のインプリメンテーションがボリュームをマウントするとき、ボリュームの一貫性が維持されていることを確認するため、基本的な一貫性チェックを実行する必要があります。 また、より高度な一貫性チェックのインプリメントを選択してもかまいません。
これらの一貫性チェックの多くは実行に相当な時間を要します。 安全なインプリメンテーションでは、ボリュームがマウントされるたびにこれらのチェックを実行する可能性がありますが、大部分のインプリメンテーションでは、ディスクを修正した前のインプリメンテーションの処理の正しさを信頼しようとします。 インプリメンテーションによっては、ボリュームが前回正常にアンマウントされたかどうかを判定することで、不必要なチェックを避ける場合もあります。 前回正常にアンマウントが行われていれば、一貫性チェックのスキップが選択されます。
ボリュームが前回正常にアンマウントされたかどうかを判定するためには、ボリュームヘッダーに含まれるさまざまなフラグビットをチェックする必要があります。 詳細については、「ボリューム属性」を参照してください。
nextCatalogID フィールドによる一貫性のチェック
HFS Plus ボリュームを多くのインプリメンテーションとの組み合わせで正常に動作させるためには、ボリュームヘッダーの nextCatalogID フィールドがカタログファイルで現在使用されているどの CNID よりも大きいことが重要です。 これを保証するアルゴリズムは以下のとおりです。
- インプリメンテーションでは、カタログファイルのすべてのリーフノードでファイルおよびフォルダレコードを繰り返し検索し、カタログに含まれるファイルまたはフォルダの最大の CNID を決定する必要があります。
- 最大の CNID 値がわかったところで、
nextCatalogID にそれよりも大きな値を設定します。
|
注意:
ボリュームヘッダーの attributes フィールドの kHFSCatalogNodeIDsReusedBit がセットされいている場合には、nextCatalogID の一貫性チェックはスキップする必要があります。
|
アロケーションファイルの一貫性のチェック
HFS Plus ボリュームを正常に動作させるためには、ファイルシステム構造によって使用されているアロケーションブロックがアロケーションファイル内で割り当て済みとしてマークされていることが重要です。 これを保証するアルゴリズムは以下のとおりです。
- インプリメンテーションではまず、アロケーションファイル内ですべてのアロケーションブロックが空きであるとマークする必要があります (一貫性チェックのパフォーマンスを向上させるため、このステップを省略することもできます。 ただし、アロケーションブロックの中には使用中とマークされていても、実際にはどのエクステントによっても使用されていないものもあります)。
- 次に、先頭の 1536 バイトと最後の 1024 バイトを含むアロケーションブロックを割り当て済みとしてマークする必要があります。 これらの領域は予約されているか、ボリュームヘッダーによって使用されます。
- 次に、すべての特殊ファイル(カタログファイル、エクステントオーバーフローファイル、アロケーションファイル、アトリビュートファイル、およびスタートアップファイル)のすべてのエクステントで使用されているアロケーションブロックを割り当て済みとしてマークする必要があります。 これらのエクステントはすべてボリュームヘッダー内に記述されています。
- 次に、カタログファイルのリーフノードで、ファイルレコード(つまり、データおよびリソースフォークに対する
HFSPlusForkData 構造体)のエクステントによって使用されているすべてのアロケーションブロックを割り当て済みとしてマークする必要があります。
- 次に、エクステントオーバーフローファイルのリーフノードで、すべてのエクステントレコードのすべてのエクステントによって使用されているすべてのアロケーションブロックを割り当て済みとしてマークする必要があります。
- 最後に、アトリビュートファイルのリーフノードで、フォークデータ属性と拡張属性に記述されているすべてのエクステントによって使用されているすべてのアロケーションブロックを割り当てる済みとしてマークする必要があります。
|
警告:
ユーザデータの消失を防ぐため、インプリメンテーションでは、前回正常にアンマウントされなかったボリュームをマウントするたびに、このチェックを実行する必要があります。 最も重要なのは、使用中のアロケーションブロックがアロケーションファイルの中でマークされているかどうかということです。 使用中でないアロケーションブロックがアロケーションファイルの中でクリアされているかどうかはそれほど重要な問題ではありません。 アロケーションブロックがアロケーションファイルによって使用中とマークされていても、実際にはどのエクステントでも使用されていないと、そのアロケーションブロックは現実的に無駄な領域になってしまいます。 しかもこれは無駄であるばかりでなく、非常に危険でもあります。
|
先頭に戻る
要約
ボリュームフォーマットの仕様は実に興味深いものです。 多岐にわたるものです。
先頭に戻る
参考資料
Inside Macintosh: Files(特に、「Data Organization on Volumes」のセクション)
Carbon ユーザ体験ドキュメントの Finder Interface Reference のセクション
Technical Note 1189: The Monster Disk Driver Technote(特に、「Secrets of the Partition Map」 のセクション
Algorithms in C、Robert Sedgewick 著、Addison-Wesley 刊、1992 年発行(特に、B ツリーのセクション)
変更履歴
先頭に戻る
ダウンロード
|

|
FastUnicodeCompare.c(43 KB)
|
ダウンロード
|
先頭に戻る
|